이미지 시퀀스( 비디오) 입력을 받아 특징을 추출하는 방법 중 3D Conv를 이용한 방법에 대한 논문이다
비디오를 사용하여 분석할 수 있는 분야는 행동인식, 추천, 검색, 순위, 이상행동 감지, 활동 이해 등이 있다
Abstract
- 저자는 대용량 지도학습 데이터셋에 대하여 3D Conv를 이용하여 쉽고 효과적으로 시공간 특징을 학습함을 제안한다
- 저자의 연구는 세가지 갈래를 찾았다
- 1. 3D conv와 2D Conv의 시공간 특징 학습을 비교
- 2. 3x3x3 conv kernel을 사용한 architectures가 가장 좋은 성능을 보임
- 3. 간단한 선형분류기를 이용하여 4개의 다른 밴치마크에서 SOTA를 달성 다른 2개의 밴치마크에서도 견줄만한 성과 달성 UCF101 데이터셋에 대하여 52.8% 정확도를 얻고 빠른 inference로 인해 계산에 매우 효율적이다.
- 최종적으로 C3D는 매우 간단하고 학습과 사용이 쉽다
1. Introduction
- 인터넷이 빠르게 성장함에 따라 매분 수많은 비디오가 공유되고 있다. 정보의 폭발에서 비디오 분석은 다양하게 활용될 수 있다. 그렇기 때문에 비슷한 대용량 비디오 작업에 일반적인 비디오 설명기(descriptor)가 필요로 하게 되었다
- 저자는 효율적인 비디오 설명기에 4가지 속성이 있어야한다고 본다
- 1. Generic : 다양한 타입의 비디오를 잘 설명해야한다
- 2. Compact : millions 비디오를 작업할 수 있도록 딱 맞아야 한다
- 3. efficient : 몇 천 개의 비디오는 real world시스템에 매분 적용될 수 있어야 한다
- 4. simple : 간단한 모델이 여야 한다 (ex : linear classifier - 저자는 linear SVM 사용)
- 기존의 연구들의 대부분은 이미지를 이용한 분석이었다 해당 방법의 문제점은 시간적(temporal) 정보를 잃어버린다는 점이었다 그래서 저자는 시공간 특징을 학습하는 3D ConvNet을 제안한다
- 이전에도 3D ConvNets을 이용한 연구가 있었지만 저자의 제안은 다양한 대용량 지도 학습 데이터셋 분석에서 좋은 성능을 보였다
2. Related Work
- Laptev and Lindeberg - spatio-temporal interest points ( STIPs) : Harris corner detector를 3D로 확장
- SIFT and HOG : 3D로 확장함 SIFT-3D, HOG3D
- Dollar et al. - Cuboids features for behavior recognition
(P. Dollar, V. Rabaud, G. Cottrell, and S. Belongie. Behavior recognition via sparse spatio-temporal features. In Proc. ICCV VS-PETS, 2005) - Sadanand and Corso - ActionBank for action recognition
(S. Sadanand and J. Corso. Action bank: A high-level representation of activity in video. In CVPR, 2012.) - Wang et al. - Dense Trajectories (iDT) 'SOTA'
시간 정보와 공간정보를 따로 처리하여 SOTA 달성 Harris corner를 3D로 확장하고 Densely-sampled 된 특징 포인트들을 optical flow를 이용하여 추적한 후 수작업으로 만들어진 궤적을 추출
성능은 좋지만 대규모 데이터 셋에서 다루기 어려움 - 계산량이 많음 - 강력한 병렬 처리기계로 인해 ConvNets는 좋은 성능을 보여왔고 human pose estimation에 대하여 이미지와 비디오에서도 좋은 성능을 보여왔다
A. Jain, J. Tompson, M. Andriluka, G. W. Taylor, and C. Bregler. Learning human pose estimation features with convolutional networks. In ICLR, 2014 - ConvNets을 이용한 연구들은 좋은 성능을 보였지만 역시 다양하고 큰 데이터셋에서는 계산이 많이 필요하게 된다
- 3D ConvNet은 full 비디오를 입력으로 받기 때문에 대용량 데이터셋에도 scaling 이 쉽다
- 기존에도 3D Conv를 이용한 실험이 있었지만 저자는 3D Conv와 3D pooling을 이용하여 시공간 정보가 처음부터 끝까지 모든 레이어에 전파될 수 있도록 하였다
3. Learning Features with 3D Convnets



- 저자는 실험을 통해 어떤 kernel을 사용함이 최적의 성능을 보이는지를 실험한다
- Conv kernel의 표현 $$ c \times l \times h \times w $$
- c : 채널의 개수
- l : 프레임의 길이
- h , w : 프레임의 높이, 넓이
- pooling kernel의 표현 $$d \times k \times k $$
- d : 시간적 깊이 ( frame 개수로 이해, 첫 번째 압축을 제외한 다음부터는 프레임 개수로 보기에는 무리가 있음)
- Common network settings
- 101개의 다른 행동에 대하여 분류
- 모든 비디오는 128 X 171로 resize ( UCF101 데이터셋에 대하여 반절 정도임)
- 비디오를 겹치지 않는 16개의 프레임으로 나누어서 네트워크에 인풋으로 사용
- $$ input : 3 \times 16 \times 128 \times 171 $$
- jittering과 random crop(3x16x112x112) 사용
- 총 5개의 conv layers와 5개의 pooling와 2개의 FCL와 마지막에 softmax 사용
- 각 5개의 conv layers의 필터 개수는 64, 128, 256, 256, 256 사용
- 적절한 padding 사용 stride 1 사용
- 모든 pooing layer는 2x2x2 max pooling stride 1 사용 - 아웃풋은 인풋에 비해 8배 압축
- 가장 첫 번째 pooling layer는 시간적 정보를 너무 빠르게 합치지 않기 위해 1x2x2 사용 ( 2D pooling)
- 두 개의 FCL은 2048의 아웃풋을 가지며
학습은 scratch부터 학습
mini-batches 30 사용
init lr : 0.003 4 epochs마다 10씩 나눔
16번의 epochs가 지나고 학습 멈춤
- Varying network architectures
- 저자가 메인으로 제안한 점은 어떤 커널이 가장 성능이 좋았냐다 그래서 Conv kernel에서 d에 해당하는 depth를 1~ 7로 변경하며 성능을 측정했다 ( depth 1은 2D와 같음)
- $$ c \times d_i \times h \times w $$
- 실험 1
- 모두 같은 kernel size d : (1,1,1,1,1 ) ( 3,3,3,3,3) (5,5,5,5,5) (7,7,7,7,7)
- 실험 2
- 증가와 감소
- (3-3-5-5-7) 증가
- (7-5-5-3-3) 감소
- 각 실험에서 파라미터 개수의 차이는 마지막에 있는 FCL의 파라미터 개수 비중이 크기 때문에 너무 작아 별 상관하지 않았다는.....

- 결론적으로 위 실험을 통해 depth는 3으로 고정하고 pooling도 첫 번째를 제외하고 2x2x2 사용하고 마지막 FCL들의 아웃풋을 4096으로 고정
- Dataset
- Sports-1M dataset에 학습 ( 가장 큰 비디오 분류 데이터셋 487개의 스포츠 종류 )
- UCF101과 비교 - Sports-1M이 5배 많은 카테고리를 가지고 100배 정도 더 많은 데이터셋
- Training
- 렘덤으로 비디오에서 5개의 2초 길이 클립 추출 각 클립은 128x171로 resize
- 학습 시에는 공간, 시간적 jittering을 위해 16 x 112 x 112로 랜덤 크롭 , 50% 로 수평 반전
- SGD mini-batch 30 사용
init lr 0.003 , 150K iter마다 2로 나눔
1.9M iter에서 학습 종료 ( 대략 13 epochs) - scratch 학습과 I380K에 대하여 pre-trained model을 fine-tuned 하여 사용


- What does C3D learn?
- 과연 3D conv가 어떤 것을 보고 판단하는지를 판별하기 위하여 deconvolution method를 이용하여 C3D를 설명함
(Visualizing and understanding convolutional networks. In ECCV, 2014) - C3D가 처음 몇 프레임에서는 모양에 초점을 맞추고 후속 프레임에서는 두드러지는 움직임을 추적한다는 것을 관찰함
- 과연 3D conv가 어떤 것을 보고 판단하는지를 판별하기 위하여 deconvolution method를 이용하여 C3D를 설명함

- 잘 보이지 않지만 첫 번째 체조 비디오의 경우 처음에는 사람에 대해 가중치가 활성화되어있고 후속 프레임으로 갈 수 록 사람의 행동에 가중치가 활성화됨을 볼 수 있음
- 두 번째 사진의 경우 눈에 활성화가 되어있고 후속 프레임에는 눈의 움직임에 가중치 활성화가 되어있음

4. Action Recognition
- C3D is compact
- C3D의 compactness를 평가하기 위해 UCF101 데이터셋에 대하여 PCA를 사용하여 더 낮은 차원으로 projection 하여 linear SVM에 사용하여 정확도를 봄
- 아래 그래프를 보면 더 낮은 차원에서 C3D의 정확도가 월등히 높은 것을 볼 수 있다
- fc6의 features를 추출하여 비디오에 대해서 좋은 일반적인 특징들을 학습하는지 보기 위해 t-SNE를 이용하여 시각화함


5. Action Similarity Labeling
- Dataset
- ASLAN dataset 사용 - 3,631개의 비디오, 432개의 액션 클래스
- 두 개의 비디오를 보고 같은 행동인지 다른 행동인지 판별
- 데이터셋 10-fold 사용
- 테스트셋에는 한번도 본적없는 비디오를 이용하기 때문에 매우 도전적인 과제임
- Features
- 비디오를 8개의 프레임이 겹쳐지는 16프레임의 비디오 클립으로 자름
- C3D에서 prob 와 fc7, fc6, pool5 에서 특징을 추출함 - 각 feature를 평균한 뒤 L2 norm을 이용하여 계산
- Classification model
- (A. Jain, J. Tompson, M. Andriluka, G. W. Taylor, and C. Bregler. Learning human pose estimation features with convolutional networks. In ICLR, 2014) 와 똑같은 설정 사용
- 4가지 타입 특징에 대하여 12개의 다른 distances를 제공( 48-차원 12 x 4 )
- 각 distances는 서로 비교될 수 없기 때문에 각각이 0의 평균과 unit variance를 갖도록 독립적으로 정규화


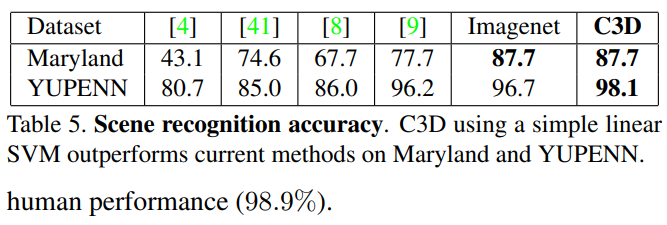
6. Scene and Object Recognition
- Datasets
- 다양한 장면 인식을 위해 두개의 벤치마크 데이터셋 사용 - YUPENN, Maryland
- object recognition에는 egocentric dataset사용 일상용품 42종
- YUPENN
- 420개의 비디오 14개의 장면 카테고리
- Maryland
- 130개의 비디오 13개의 장면 카테고리
- Classification model
- 모든 데이터셋에 대하여 같은 특징 추출 설정 사용하고 선형 SVM으로 분류
- leave-one-out evaluation 사용 (leave-one-out evaluation protocol as described by the authors of these datasets.)
- 비디오를 16개의 프레임으로 자르고 각 클립에서 가장 잘 발생하는 레이블을 정답 레이블로 설정
클립에서 가장 자주 발생하는 레이블이 8 프레임 미만이라면 객체가 없는 negative 클립으로 간주하고 훈련과 테스팅 모두에서 버렸다
7. Runtime Analysis

Appendix
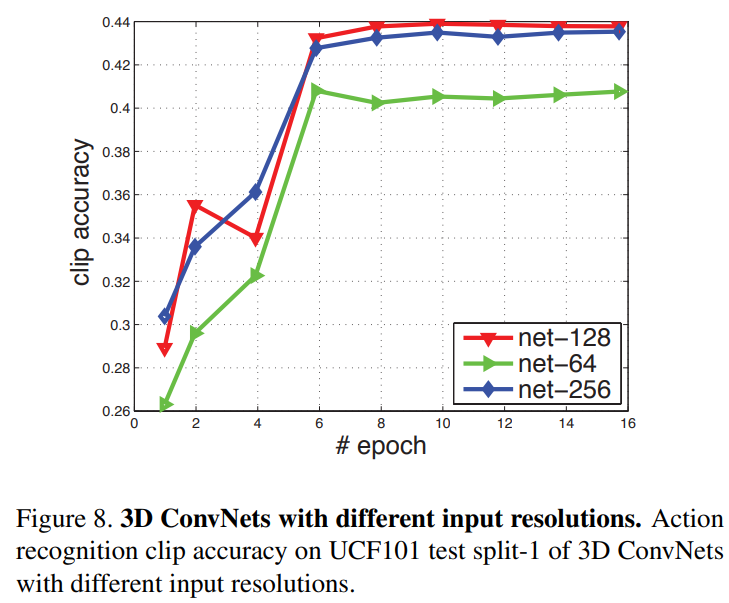
- 인풋 해상도의 효과

- C3D가 학습한 특징 시각화
- conv2 a
- low-level motion pattenrns 학습 주로 움직임의 edges, blobs, short changes, edge orientation changes, color changes - conv3b
- 좀 더 큰 모서리 움직임 패턴, textures, body parts, trajectories - conv5b
- 움직이는 원형 물체, 자전거 타기와 같은, 움직임과 같은 더 복잡한 움직임 패턴을 학습함
- conv2 a






'Machine Learning > 논문 리뷰' 카테고리의 다른 글
| (9) CSPNet : A New Backbone that Can Enhance Learning capability of CNN (2019) (0) | 2022.07.20 |
|---|---|
| (8) YOLOX : Exceeding YOLO Series in 2021 (2021) (0) | 2022.06.12 |
| (6) DenseNet : Densly Connected Convolutional Networks (2017) (0) | 2022.04.10 |
| (5) ResNet : Deep Residual Learning for Image Recognition(2015) (0) | 2022.03.14 |
| (4) GoogLeNet(Goog-Le-Net) Going Deeper with Convolutions (0) | 2022.02.20 |