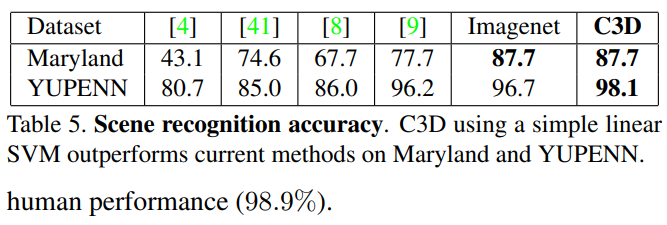
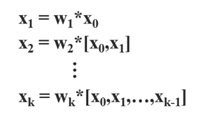딥러닝을 활용하여 자동차 번호판을 추출하고 인식(OCR)을 테스트 해 보았을 때
추출은 잘 되지만 인식은 잘 되지 않는 경우가 많았다.
그래서 어떻게 하면 더 간단하게 이미지를 변형할 수 있을까 생각을 하며 테스트를 해보았다
1. 추출된 번호판에 대해서 진행한다
2. 번호판 사이 간격이 존재한다는 가정
3. 번호판을 하나의 단어만을 유추 할 수 있도록 쪼개보자
단순 테스트용으로 내용은 부실합니다 .ㅎㅎ
순서
1. 이미지를 gray scale로 변환
2. Blur를 적용하여 불필요한 엣지를 줄임
3. 엣지를 찾고
4. 외곽선을 검출하고
5. 외곽선 결과를 4개의 점으로 받아 넓이가 큰 순서로 정렬
6. 가장큰 외곽선을 엣지추출한 이미지에서 추출
7. Blur와 closing을 통해 이미지에 노이즈를 줄임
8. x, y 축 각각 좌표별 원소의 합을 구해 정보가 적은 영역을 찾기
9. 정보가 적은 영역 제거
10. 다시 x,y축 각각 좌표별 원소의 합을 구해서 plot 해보기
사용한 차량 번호는 없는 번호입니다 ~
1 ~ 2 - 이미지 전처리


3. edge 추출

4 ~ 5 외곽선 검출 하고 넓이로 정렬
contours, _ = cv2.findContours(edge.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
6. 가장 큰 외곽선 선택 하여 해당 영역만 추출

7. 노이즈 제거를 위해 blur 적용 후 closing

8. x축, y축 원소의 개수 확인

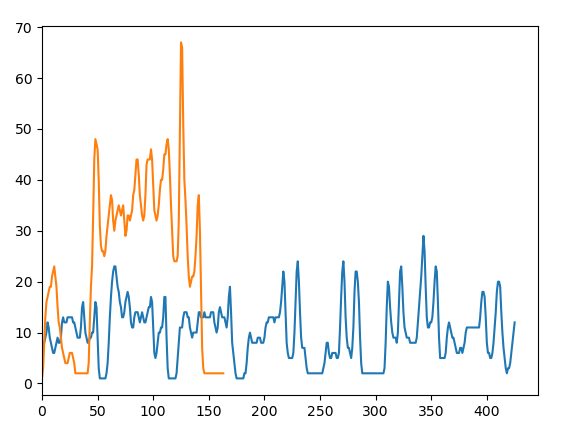
plot을 보면 이미지에서 아무 정보가 없는 부분의 원소의 합이 0에 가깝게 나온다는 것을 확인 할 수 있다.
그렇다면 처음 ~ 0까지 정보와 맨뒤에서 0이 아닌 원소에 대해서찾는 다면 원하는 번호만 존재하는 영역을 뽑을 수 있겠다
9. 정보가 적은 영역 제거 후 다시 원소의 개수 확인
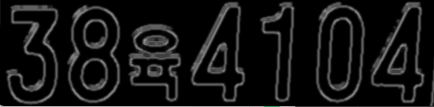
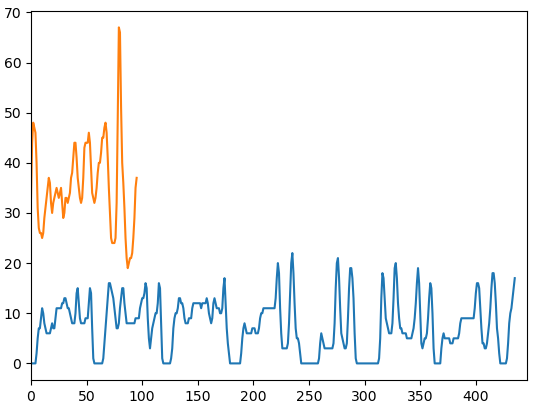
그래프에서 노란선은 y축에 대한 원소의 합 파란선은 x축에 대한 원소의 합이다.
먼저 x 축에 대하여 보면
3의 정보가 있는 영역은 x축 0 ~ 50까지라고 볼 수 있다
8의 정보가 있는 영역은 x축 50 ~ 120까지라고 볼 수 있다
이런식으로 각 7자리 영역에 대해서 유추를 해볼 수 있다.
워낙 테스트용으로 만들어본 내용이라 실제 사용은 불가능 하다
1. 외곽선 검출에서 가장 넓은 영역이 번호판이 아닐 수 있다.
2. 차량 번호판은 다양하기 때문에 각 작업에 다른 처리가 들어가야한다.
3. 번호판이 기울어져 있다면 x 축에대해서 원소의 개수가없는 영역이 줄어들 것이다.
(내용 추가)
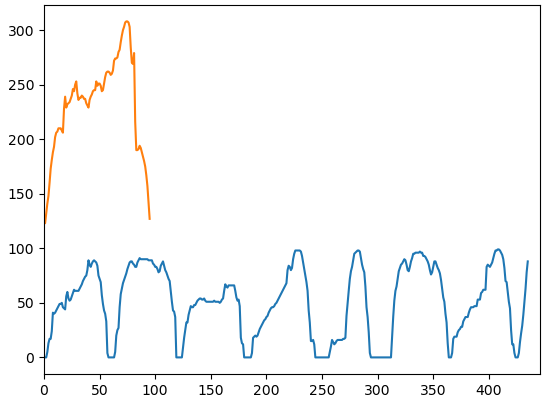
floodFill을 활용한 정보 부곽
번호판에서 0,0 위치부터 0에 해당하는 값을255로 변경하고 bitwise not으로 색상을 반전시켰다


'Machine Learning > Computer Vision' 카테고리의 다른 글
| (2) OpenCV C++ - image 결합, 외곽선 검출 (0) | 2023.09.13 |
|---|---|
| (1) OpenCV C++ - 기초 ( imread, imshow, cvtColor, resize) (0) | 2023.09.08 |
| (11) OpenCV python - 원근(투영) 변환 - perspective (projection) transform (0) | 2022.06.07 |
| (에러를 딛고 깨달은) opencv perspective transform 후 선 그린 후 원본에서 해당 선의 위치 구하기 - 역변환 하기, 점 변환 (0) | 2022.03.10 |
| (10) OpenCV python - 색상 범위 추출 - inRange (0) | 2021.11.27 |