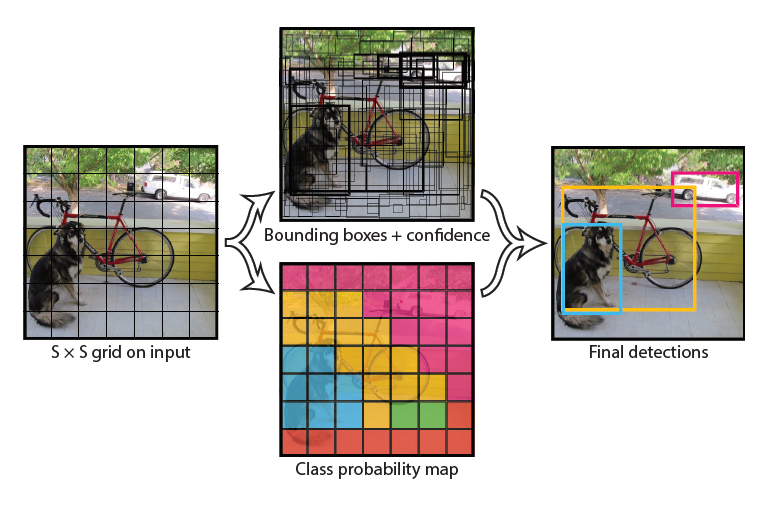
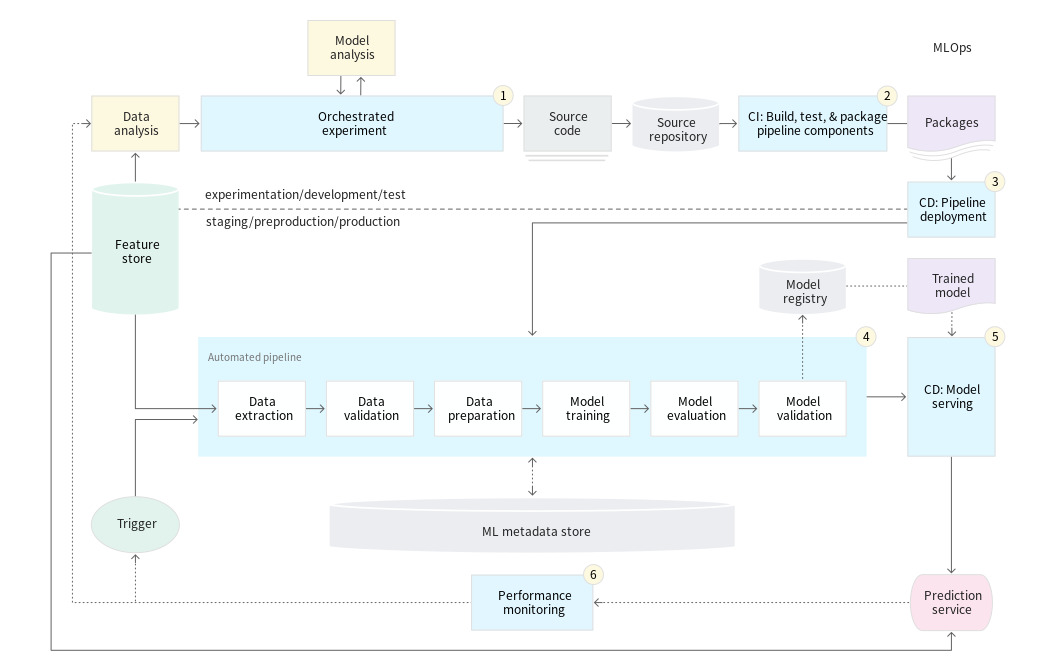
인공지능의 기본인 Norm 이다 .
처음 Norm을 공부할 때는 L1, L2 Norm에 대해서만 알고있었다.
그런데 Gradient Descent를 공부하니 L1,L2 Loss 가 나와서 둘이 같은것인줄 알았지만 달랐다.
또 다른 말이 있다. L1 L2 regularization 이다.
이렇게 앞에 L1 L2 는 같지만 뒤에 붙는 말이 다른 경우가 많다 그래서 Norm이란 무엇이고 각각이 어떻게 다른지에 대하여 정리하였다.
Norm 이란?
백터의 크기 또는 길이를 측정하는 방법
한 점에서 어떤 벡터까지의 거리를 구할 때 사용할 수 있다
Linear regression을 예로 들면 어떤 Hypothesis H(x)와 실제 정답데이터까지의 거리를 측정하여 다음 Gradient Descent의 강도를 조절 할 수 있다.
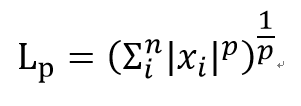
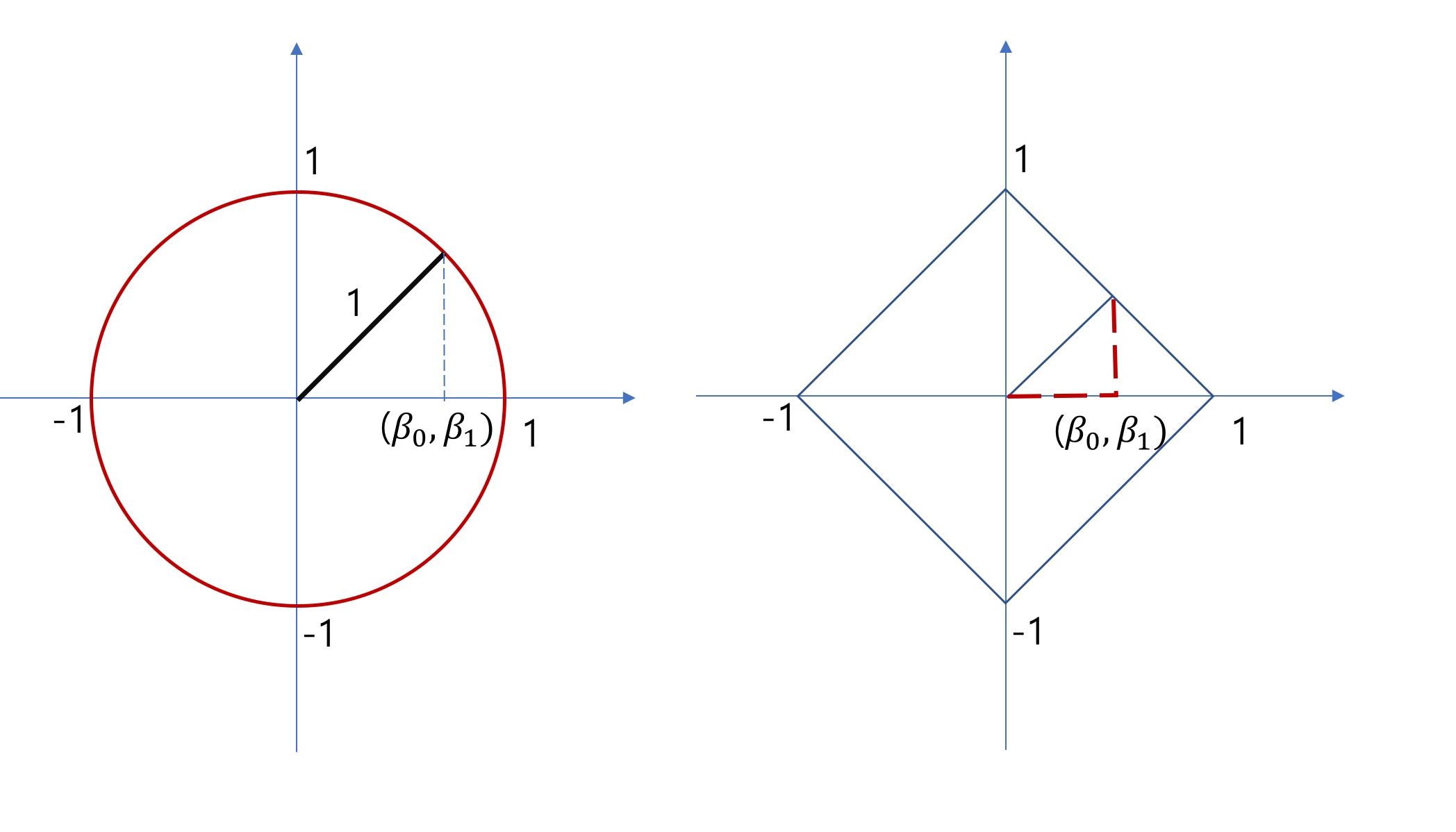
L1 Norm
Manhattan Distance, Taxicab geometry라고도 불린다.
L1 은 절댓값과 연관되어있다.
위의 Norm 수식에 p=1 을 대입하여 보면 L1 = x의 모든 절댓값들의 합 이 된다
L2 Norm
Euclidean Norm 이라고도 불린다.
L2 는 제곱과 연관되어있다.
위의 Norm 수식에 p=2 를 대입하여 보면 L2 = x제곱의 모든 합에 제곱근 이된다.
Maxium Norm (최대 놈)
Maxium Norm 은 위의 Norm 수식에 p --> 무한대 를 대입하여 보면
L _inf = max(|x1|,|x2|,|x3|....|xn|) 백터 성분의 최대값을 구하게 된다
Loss
loss 는 Hypothesis(가설)와 실제 데이터사이의 차이를 구하여 방정식에 적용하여 최대한 데이터와 가설과의 차이를 줄이기 위하여 사용된다.
L1 Loss
실제 데이터와 가설과의 차이를 절대값을 통해 더한다 Least Absolute Deviations 라고도 한다
데이터의 이상치가 있을 경우 L1은 L2보다 이상치에 영향이 적다 - 제곱근 때문
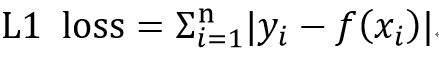
L2 Loss
실제 데이터와 가설과의 차이를 제곱을 이용하여 더한다 Least Square Error라고도 한다
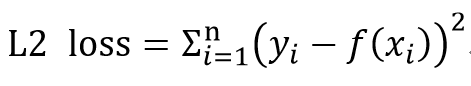
L2 Norm 과 다른점은 loss는 벡터 사이의 에러를 효과적으로 구하기 위한것이지 절대적으로 값을 구하자는게 아니다.
그러므로 루트(제곱근)이 빠졌다.
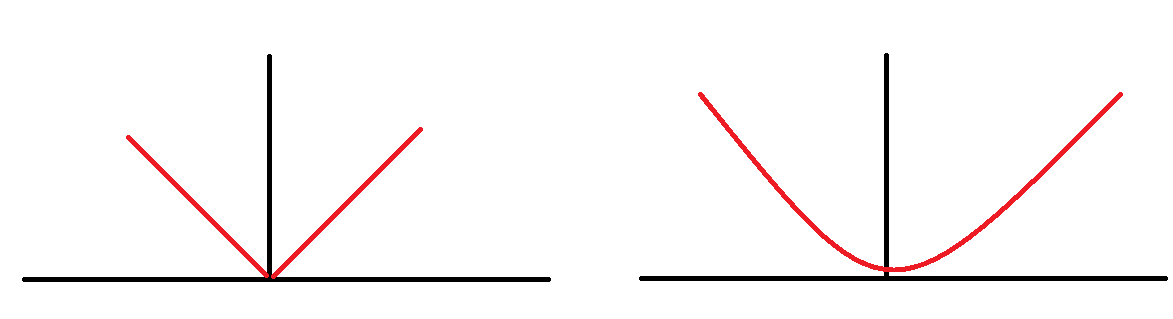
위의 그림은 L1 loss 와 L2 loss 로 생성될 수 있는 loss function의 모양중 하나이다.
L1은 절댓값을 이용하다 보니 특정 지점에서 선형적이지 않고 약간 뾰족한 모양이 만들어진다 비선형에는 미분을 적용할 수 없다
L2는 제곱을 이용하다 보니 계속하여 선형적이다.
그러므로 경사하강에서 미분을 적용해야할 때 L2가 더 효과적일 수 있다. (고유벡터 조심)
L1, L2 regularization
정규화는 overffiting을 방지하기 위한 중요한 기법이다.
각 cost function에 정규화 항을 추가하여 더해준다
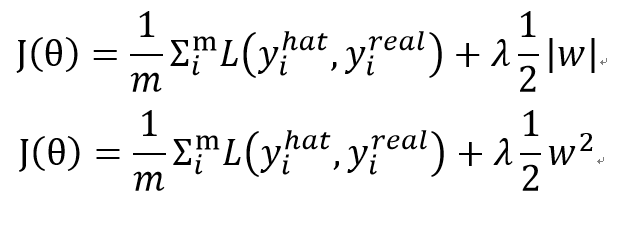
각 loss function의 결과에 hyperparameter lambda를 곱해준 정규화 항을 더하였다
a = [ 0.25, 0.25, 0.25, 0.25]
b = [ 0.5 0.5 , 0 ,0 ]
일 때 두 벡터의 L1 norm 은 모두 1이 나온다.
하지만 L2의 경우는 두 벡터의 결과값이 다르다 .
제곱을 이용하는 L2 Norm의 경우 L2는 각 벡터에 대하여 unique한 값이 나오는 반면 L1은 경우에 따라 어떤 항이 없어도 같은 결과가 나올 수 있다.
그렇게 L1 Norm 은 Feature selection의 효과가 있다
만약 j(a) = 4a1 + 5a2 + a3 가 나왔을 때 L1 Regularization을 추가하면 a2 또는 a3 가 없어도 j(a)의 결과가 같은 값을 찾을 수 있다. 결과적으로 L1 Regularization 항이 1a1 - 5a2 - a3 가 되어도 j(a)의 결과가 같다면 결과적으로 j(a) = 5a1 이 될 수 있다. ( a2 와 a3 는 feature selection에 의해 사라질 수 있다)
참조
https://seongkyun.github.io/study/2019/04/18/l1_l2/"
'Machine Learning > AI를 위한 수학' 카테고리의 다른 글
| (1) 딥러닝 구현 기초 - 데이터 (0) | 2022.01.15 |
|---|