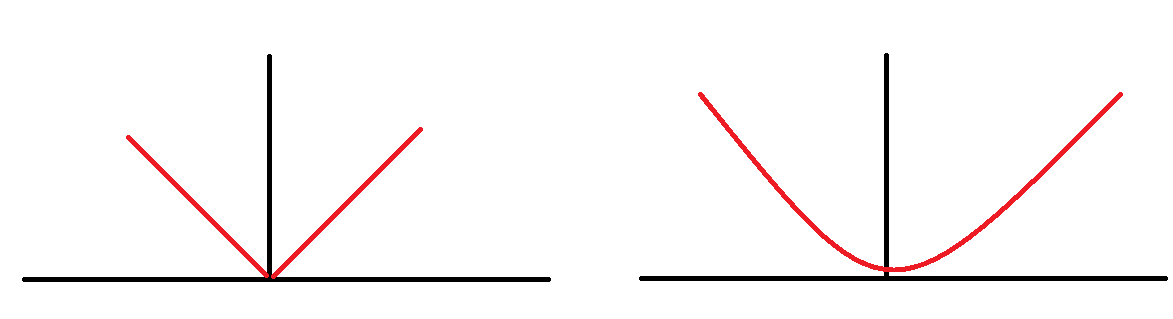
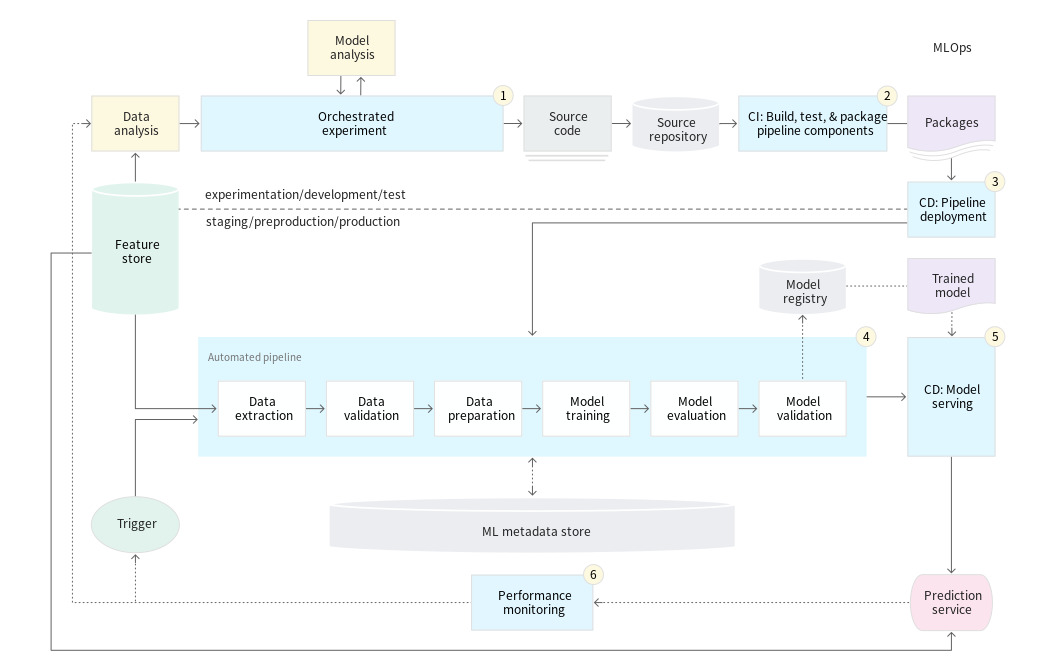
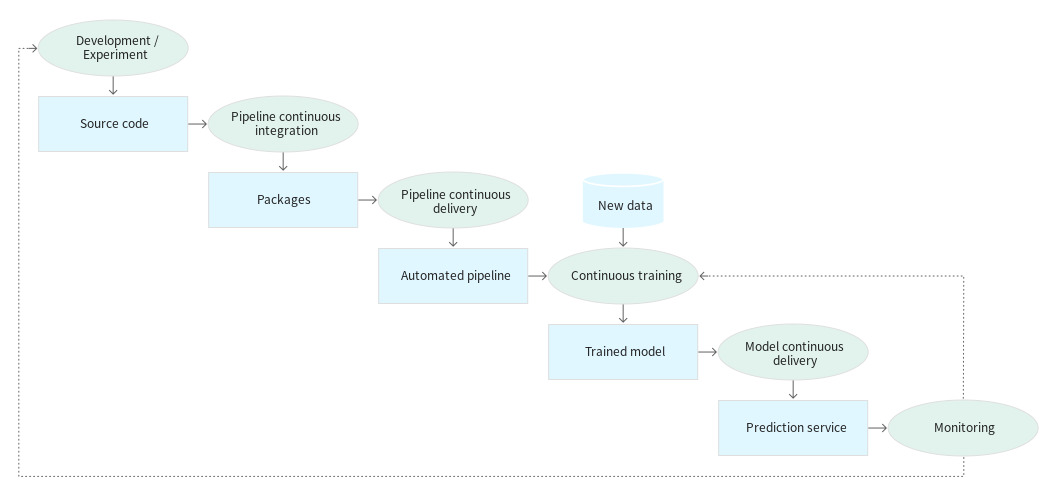
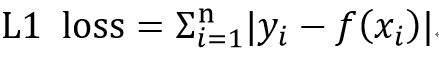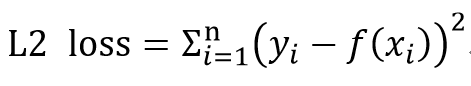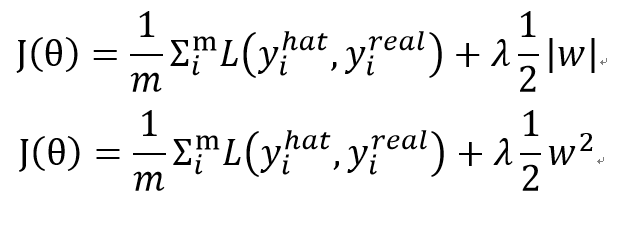요즘에는 클라우드 PC에서 작업을 주로 한다
저사양의 GPU가 없는 노트북으로 간편하게 돌아다니고
모든 코드는 클라우드에서 실행시킨다
그런데 윈도우는 상관이 없지만 리눅스의 경우 클라우드에 접속하여 코드를 하려면 사전 준비를 해야 편하게 코딩을 할 수 있다
리눅스로 코딩하는 법을 나열하자면
1. vi 으로 코딩하기
- ㅎㅎ vi는 작은거 하나씩 고칠 때 사용하자.... 매우 비효율적이다
2. jupyter notebook을 이용하자 !
- 나쁘지 않다 jupyter notebook은 테스트를 할 때 매우 편하기에 사용하기에 나쁘지 않은것 같다
하지만 이쁘고 이쁘고 한눈에 알아볼 수 있게 코딩을 하는게 더 실수를 줄이기 좋다 ㅎㅎ
3. Visual Studio Code를 이용하자 !
- Visual Studio Code - VSC 는 많은 확장프로그램을 지원해주기 때문에 이쁘고 효율적으로 코딩을 할 수 있다 !
쥬피터와 다른점은 변수, 클래스, 함수 등의 색을 다르게 볼 수 있다 !
- 코드상에 오류가 있다면 빨간물결이 나온다 ! 매우 중요하다 ...
- 디버깅이 가능하다 !
- Python 뿐만 아니라 JAVA, C, C++ 등등 여러가지 언어로 코딩할 수 있다 !
- Jupyter notebook 도 VSC에서 사용할 수 있다 !
이제 원격 설정을 시작해 보자 !!!
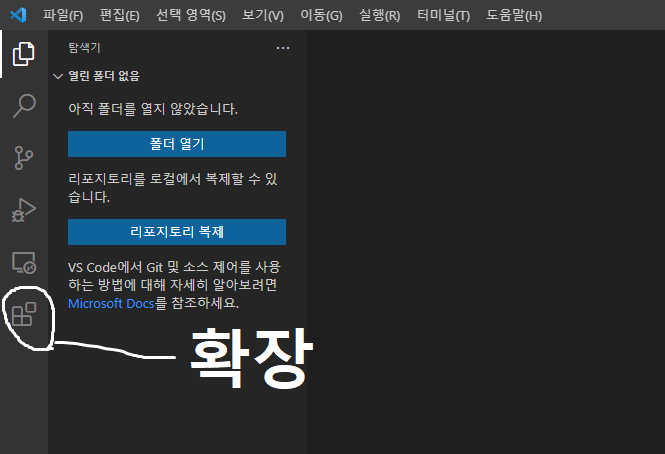
VSC를 실행시키고 왼쪽 확장 탭에 들어간다
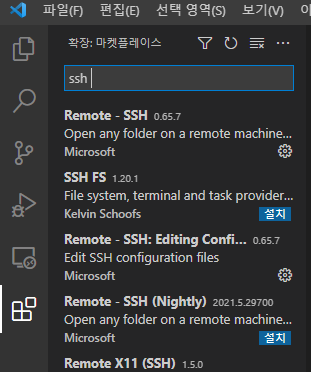
확장탭의 검색창에 SSH 또는 Remote를 검색하면
Remote - SSH 가 나온다 해당 extension을 설치한다 !

키보드에서 F1 키를 누르면 위와같은 창이 나오고 창에 Remote-SSH를 입력하면
Remote-ssh: Connect to Host 가 나오게 된다 !
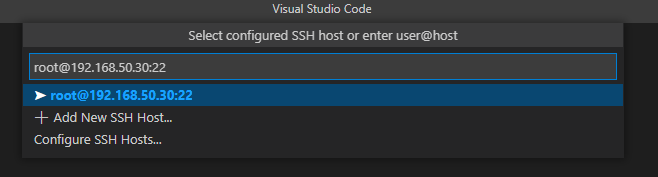
Connect to Host를 클릭하면 SSH 접속을 할 서버 정보를 입력해야한다
나는 원격 접속지의 계정 root에 IP는 192.168.50.30에 접속할 것이다
여기서 원격지의 포트는 SSH 기본 설정 포트인 22번이다
계정이름 : root
원격지 주소 : 192.168.50.30
원격지 포트 : 22
접속 정보를 다 입력하고 엔터를 누르면 접속을 하게된다
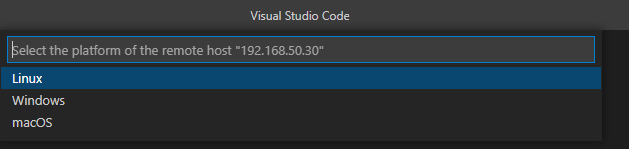
원격지의 운영체재를 고르라고 한다 내가 접속할 서버는 Linux이기 떄문에 Linux를 선택한다
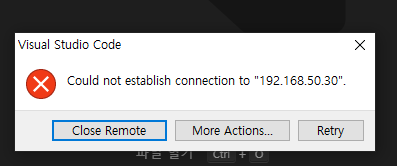
만약 이런 연결이 되지 않는다는 창이 나온다면 역시 설정을 잘 했는지 또는 방화벽은 허용이 되어있는지 다시한번 체크해보길 바란다
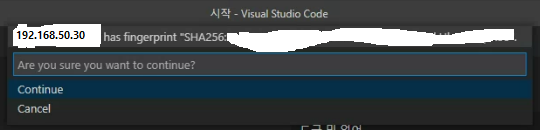
Linux를 선택을 하면 위의 사진과 같이 SHA256키를 알려주고 연결을 하겠냐고 다시 물어본다
Continue를 선택하자
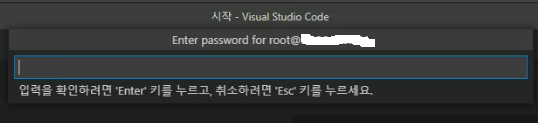
위의 사진과 같이 비밀번호를 입력하라고 나오면 해당 계정(root)의 비밀번호를 입력한다 !
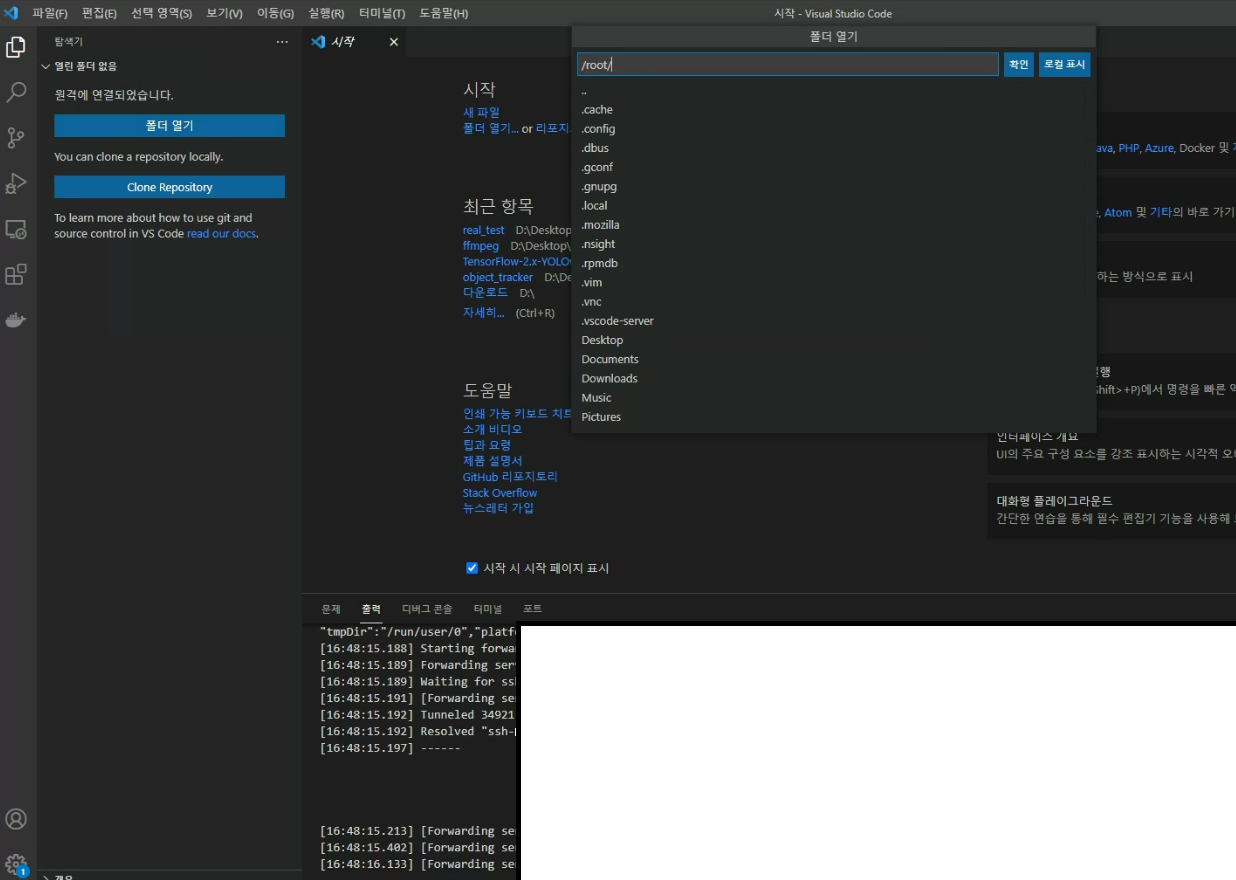
그럼 연결이 완료되고 폴더 열기를 선택하면 위와같이 연결된 서버의 디렉토리 리스트가 나오게 된다
이제 원하는 디렉터리를 열고 작업을 시작하면 된다 !
그런데 여기서 디렉터리를 선택하면 다시 비밀번호를 입력하라는 창이 나오게 된다
다시 입력하는게 귀찮다면 SSH Key를 생성하여 서버와 로컬에 설정을 해줘야한다
하지만 매우 귀찮기 때문에 계속 치고 들어가겠다
계속 비밀번호를 입력하는게 귀찮으신 분은 구글에
vsc ssh save password 를 검색해서 따라해보시기를 바란다
'infra > Tools' 카테고리의 다른 글
| [git] 기초 설명과 사용법 (0) | 2021.09.14 |
|---|---|
| [Xshell] 2. Xshell 로깅 logging (0) | 2021.06.19 |
| [Xshell] 1. Xshell 다운 및 사용 방법 (0) | 2021.06.19 |