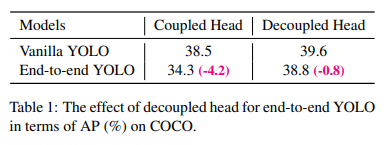
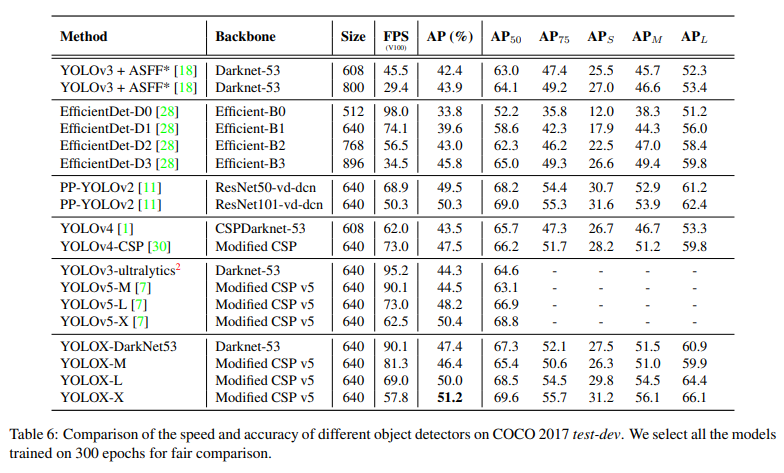
C기반 언어를 사용하는 이유중 개인적인 생각으로 가장 중요한 부분이 포인터라고 생각한다 .
포인터를 이용하여 메모리 주소값에 직접 접근하여 프로그램의 효율을 상승시킬 수 있다.
포인터란?
- 포인터는 값 자체가 아니라 값의 주소를 저장하는 변수이다.
- 주소연산자(&)를 변수 앞에 붙이면 그 변수의 주소를 알아낼 수 있다.
- cout을 사용할 때 주소값은 컴파일러에 따라 16진수 또는 10진수로 표현된다
- * 기호는 곱하기를 뜻하기도 하지만 포인터에서는 해당 메모리 주소에 들어있는 값을 의미한다
*메모리주소변수 = 100 - & 기호는 and를 뜻하기도 하지만 해당 변수의 메모리 주소를 의미한다
&값변수 = 00000079CA8FF534
int main() {
using namespace std;
int donuts = 8;
double cups = 4.5;
// 변수의 주소를 알고싶다면 해당 변수앞에 &를 붙여라
cout << "donuts : " << donuts;
cout << " donuts의 주소 : " << &donuts << endl; // 000000B526CFF7C4
cout << " donuts의 사이즈 : " << sizeof(donuts) << endl; // 4 Byte
cout << "cups: " << cups;
cout << " cups의 주소 : " << &cups << endl; // 000000B526CFF7E8
cout << " cups의 사이즈 : " << sizeof(cups) << endl; // 8 Byte
return 0;
}int main() {
using namespace std;
int updates = 6;
int* p_updates; // int형을 지시하는 포인터 선언
p_updates = &updates; // int형의 주소를 포인터에 대입
cout << "값 : updates = " << updates; // 해당 변수에 대입된 값
cout << ", p_updates = " << p_updates << endl; // 해당 주소의 값 ( 포인터 )
cout << "주소: &updates = " << &updates; // 변수가 저장된 메모리의 주소
cout << ", *p_updates = " << *p_updates << endl; // 메모리 주소에 저장된 값
// 포인터를 사용하여 값 변경
*p_updates = *p_updates + 1; // 메모리주소에 저장된 값에 더하기 1 을 함
cout << "변경된 updates = " << updates << endl; // updates 의 메모리에 접근하여 값을 + 1 했기 때문에 7을 출력
return 0;
}- int* a 에서 a는 int형을 가르키는 포인터이다
- 포인터 변수는 그냥 단순한 포인터가 아니라, 항상 어떤 데이터형을 지시하는 포인터라고 해야한다
- char형의 주소와 double형의 주소는 크기가 같다. 그렇기에 특정 주소의 크기나 값만 가지고는 그 주소에 저장되있는 변수의 크기나 종류를 알 수 없다
int main() {
using namespace std;
int* ptr;
ptr = (int*)0xB80000000; // 포인터에 직접 주소를 매핑하려면 이렇게 int형을 가르키는 주소라고 데이터타입 형변환이 필요하다
}int main() {
using namespace std;
// ptr이라는 메모리주소 변수에 int형이 필요할 때
// 이렇게 초기화를 하면 시스템에서 알아서 int형에 맞는 사이즈의 메모리를 찾아서 ptr에 대입해준다
int* ptr1 = new int; // ptr1은 데이터객체를(data object)를 지시한다
// 00000153F2AF6590
cout << ptr1 << endl;
int higgens;
int* ptr2 = &higgens; // ptr2에 이런식으로 주소값을 대입할 수 있다.
// 위의 두 방식이 다른 점은 ptr1의 경우
// 오직 ptr1을 통해서만 (변수가없기때문에) 해당 값에 접근할 수 있다
// 하지만 higgens를 이용한 경우
// 해당 값에 접근할 수 있는 방식이 higgens를 이용하는 법과 ptr2를 이용하는 방법 두가지가 있게된다
return 0;
}int main() {
using namespace std;
int nights = 1001;
int* pt = new int;
*pt = 1001;
double* pd = new double;
*pd = 10000001.0;
cout << "nights의 값 : " << nights;
cout << " nights의 메모리 위치 : " << &nights << endl;;
cout << "int형 값 : " << *pt << " : 메모리의 위치 : " << pt << endl;
cout << "double형의 값 : " << *pd;
cout << "메모리 위치 : " << pd << endl;
cout << "포인터 pd의 메모리 위치 : " << &pd << endl;
cout << "pt의 크기 : " << sizeof(pt);// 8을 나타낸다 - 데이터 객체의 사이즈이기 떄문
cout << " *pt의 크기 : " << sizeof(*pt) << endl; // 4를 나타낸다 - int형의 사이즈이기 때문
cout << "pd의 크기 : " << sizeof(pd); // 8을 나타낸다 - 데이터 객체의 사이즈이기 떄문
cout << " *pd의 크기 : " << sizeof(*pd) << endl; // 8을 나타낸다 - double형의 사이즈이기 때문
return 0;
}new로 생성한 메모리를 해제하는 delete
int* ps = new int;
delete ps ; // 정상
delete ps ; // 이미 해제되었기 때문에 비정상 에러
int jugs = 5;
int * pi = &jugs;
delete pi; // new로 생성한 데이터 객체가아니기 때문에 비정상 에러'개발언어 > C++' 카테고리의 다른 글
| (C++) 6. cctype 라이브러리 (0) | 2023.09.08 |
|---|---|
| (C++) 5. for, while, do while, if, if else, (0) | 2023.09.07 |
| (C++) 4. Vector(C++98), Array(C++11) Template Class (0) | 2023.09.07 |
| (C++) 3. 동적 배열과 동적 구조체 (0) | 2023.09.07 |
| (C++) 1. Struct(구조체), Union(공용체), Enum(열거체) (0) | 2023.09.06 |