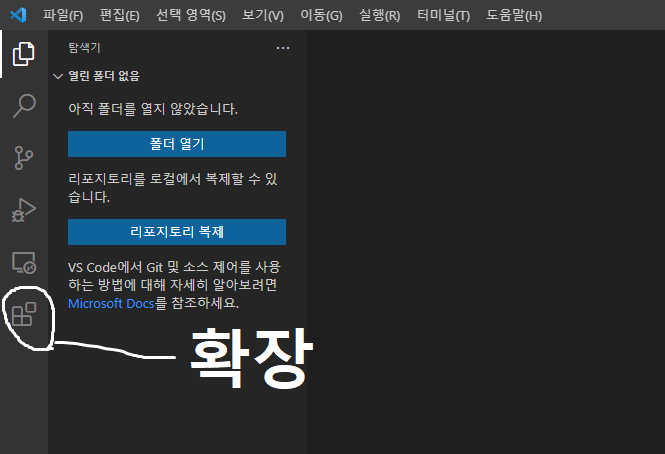
대표적인 형상 관리 도구 - 형상 관리란? : 코드의 묶음을 하나의 그림으로 보면 처음으로 제작한 그림(코드)은 버전 1.0 이 되고 해당 그림(코드)을 약간 변형하여 그림에 스티커를 붙였다 하면 이전에 그림이 어떤 모양이었는지를 알고 있다면 기존의 그림을 복원하기가 쉬울 것이다
branch(나뭇 가지)와 PR(Pull Request) - github의 경우 public(개방형)으로 만든 코드 묶음을 자유롭게 사용할 수 있고 fork라는 복사와 같은 기능을 통해 해당 public 코드 묶음을 자신만의 코드인 branch로 생성할 수 있다 - 또한 PR(Pull Request)이라는 기능을 통해 자신의 코드 수정사항을 github에 적용하기 전에 다른 사람의 의견을 물어본 후 적용시킬 수 있다. 또한 해당 PR을 통해 코드의 수정 부분과 개선 방안 등을 메신저 형식으로 쉽게 사용할 수 있다
2. git 의 작동 방식
출처 : https://opentutorials.org/module/3963/24425
Working directiory - 자신이 작업하는 PC의 폴더이다 - 해당 폴더를 기준으로 git을 사용하겠다는 명령이 필요하다 ( git init )
Staging area - 자신이 작업한 코드의 어떤 부분이 수정되고 삭제되고 추가됐는지 변경된 사항을 저장한다
Local repo - local git 저장소이다 - Staging area에서 전송받은 변경사항을 기록해놓는다 ( 메세지 : "첫 커밋", commit version : 24369y273ehdfunsz9u23.......)
remote repo - 원격 git 저장소이다 대표적으로 github과 gitlab이 있다 - 원격에 저장하는 이유의 장점은 공유이다. - 여러 사람에게 자신의 코드를 보여줄 수 있고 여러 사람이 같이 프로젝트를 진행할 수 있다
3. 기본 명령어
git init
- 코딩에서 변수를 초기화하는 것과 똑같다 git이라는 것을 사용하기 위해 초기화시킨다 (int number = 0 ) - 해당 폴더에서 git init을 입력하면 해당 폴더를 git local repo라고 인식시킨다 - git init 명령어를 실행하면 다음과 같이 git bash에 괄호( ) 안에 master라는 항목이 적혀있다 - git의 기본 branch의 이름은 master이다 ( 최근 main으로 바꿔 쓰는 것을 권장 git branch -M main)
git add
- git add 뒤에 . 을 붙이면 해당 폴더 안에 있는 모든 파일을 working directory에서 stage area에 기록한다는 뜻이다
git commit
- git commit -m "메시지" -m 옵션을 통해 이번 commit에 메모를 남긴다 - commit이 완료되면 어떤 파일이 변경되고 생성되고 삭제되고 등등 사항들이 나온다 - 대용량 파일을 commit 하려면 추가적인 설정이 필요하다
git remote add [원격지 별명] [원격지 주소]
- 위의 명령어는 test1이라는 별명으로 나의 원격지 깃헙 repo를 연결하였다 - 별명은 자신이 원하는 어떤 것이든 해도 된다
git push [원격지 별명 또는 주소] [local repo이름] - push 밀어 넣는다 - 원격지에 - local repo를
호스트 OS상에 논리적인 구획을 만들고 애플리케이션을 작동시키기 위해 필요한 라이브러리나 애플리케이션을 하나로 모아, 마치 별도의 서버인 것처럼 사용할 수 있게 만든 것
호스트 OS의 리소스를 논리적으로 분리하고 오버헤드가 적기 때문에 고속으로 작동한다
호스트형 서버 가상화
위의 그림은 과거 많이 사용된 대표적인 가상화 툴인 virtual box의 구조이다.
사용해본 사람은 느꼈듯이 가상환경을 만들고 부팅을 진행하는데 꽤 시간이 소모된다
각 가상 환경마다 각각의 OS를 가동하고 있기 때문에 overhead가 크다
컨테이너형 서버 가상화
도커의 구조는 호스트 OS에 의존하는 형식이다.
virtualbox가 초기 시작할 때 " 이 부분은 내 거야 " 하고 차지하고 시작하는 것과는 다르게 도커는 호스트와 대부분의 리소스를 공유한다
호스트 OS의 사용자를 추가하는 느낌
하이퍼바이저형 가상화
호스트형 서버 가상화와 비슷한 모양이지만 호스트 OS가 빠지고 각각의 가상 환경에 OS가 있다.
호스트 OS없이 각 가상 환경마다 별도의 OS가 하드웨어를 직접 제어하기 때문에 자원을 효율적으로 사용할 수 있다.
docker와는 지향하는 바가 다르다. 하이퍼바이저형은 서로 다른 환경을 어떻게 효율적으로 emulate 할지라는 점을 지향하고 있다
2. docker 개요
애플리케이션의 이식성 - portability - 기존의 water fall형 개발방식에서는 애플리케이션 개발 환경과 테스트 환경, 실제 서비스 환경의 환경이 모두 달랐다. 그렇기에 각각의 과정마다 애플리케이션에 문제가 발생할 확률이 높았다 - docker의 경우 docker file 형태로 환경을 구성하고 git 같은 CI를 이용하여 애플리케이션 개발부터 실제 서비스 환경까지 모두 같은 docker file을 이용하여 제작하므로 환경의 다름으로 인한 문제가 발생하지 않는다 - 이러한 환경의 제약이 많은 어플리케이션일수록 docker를 이용한 배포가 효과를 발휘한다
3. docker의 기능
Build - 이미지를 만드는 기능 - 하나의 이미지는 하나의 어플리케이션을 넣어 두고 여러 개의 컨테이너를 조합하여 서비스 구축을 권장 ( CentOS , Ubuntu, ......) - docker 이미지의 경우 명령어를 통해 수동으로 만들 수도 있지만 CI를 위하여 docker file형태로 작성하는 것을 권장한다 - docker는 이미지를 겹쳐서 새로운 이미지를 만들 수 있다 - docker는 각 이미지를 차분(이미지 레이어)로 관리하기 때문에 각각의 겹치는 부분에서 변경된 부분만을 가진다. - CentOS + MySQL(CentOS) = CentOS + MySQL
Ship - 이미지를 공유하는 기능 - docker 이미지는 docker 레지스트리에서 공유할 수 있다 docker 공식 레지스트리인 docker hub에서는 CentOS나 Ubuntu 같은 Linux배포판의 기본 기능을 제공하는 베이스 이미지를 배포하고 있다 - 이러한 베이스 이미지에 독자적인 MySQL이라던지 Jupyter 같은 독자적인 docker 이미지를 만들어 가는 것이다 - docker hub는 git과 연계할 수 있다. git hub 상에서 Docker file을 관리하고 거기서 Docker 이미지를 자동으로 생성하여 Docker Hub에서 공개하는 것도 가능하다 ( Automated Build )
Run - 컨테이너를 작동하는 기능 - Docker의 경우 이미 움직이고 있는 OS 상에서 프로세스를 실행시키는 것과 거의 똑같은 속도로 빨리 실행시킬 수 있다 - Docker는 하나의 Linux 커널을 여러 개의 컨테이너에서 공유하고 있다 - 컨테이너 안에서 작동하는 프로세스를 하나의 그룹으로 관리하고 각 그룹마다 각각의 파일 시스템이나 호스트명, 네트워크를 할당하고 있다 - 그룹이 다르면 프로세스나 파일에 대한 액세스를 할 수 없다 - 위의 컨테이너의 독립을 위해 Linux의 커널 기능인 namespace, cgoups를 이용한다 - docker component에는 Docker Engine, Docker Registry, Docker Compose, Docker Machine, Docker Swarm이 있다 각 기능은 추후 정리하겠다
4. Docker의 작동 구조
컨테이너를 구획화하는 장치 - namespace - 컨테이너를 구획화하는 장치는 Linux kernel의 namespace라는 기능을 사용한다 - 한 덩어리의 데이터에 이름을 붙여 분할함으로써 충돌 가능성을 줄이고, 쉽게 참조할 수 있게 하는 개념, 이름과 연결된 실체는 그 이름이 어떤 namespace에 속해 있는지 고유하게 정해진다 - namespace가 다르면 동일한 이름이라도 다른 실체로 처리된다
- namespace의 주된 기능
PID namespace : Linux에서 각 프로세스에 할당된 고유한 PID(process ID)를 격리한다 - namespace가 다른 프로세스끼리는 서로 액세스 할 수 없다
Network namespace : 네트워크 디바이스, IP 주소, 포트 번호, 라우팅 테이블, 필터링 테이블 등과 같은 네트워크 리소스를 격리된 namespace마다 독립적으로 가질 수 있다 - - 호스트 OS상에 사용 중인 포트가 있더라도 컨테이너 안에서 동일한 번호의 포트를 사용할 수 있다
UID namespace : 사용자 ID와 그룹 ID를 namespace 별로 독립적으로 가질 수 있다 - 컨테이너 안의 UID/GID가 0인 root 사용자를 호스트 OS 상에서는 일반 사용자로서 취급할 수 있다 - namespace 안의 root 계정은 호스트 OS에 대해서는 관리 권한을 일절 갖지 않는다 - 보안적 요소
MOUNT namespace : MOUNT namespace에 격리된 파일 시스템 트리를 만든다 마찬가지로 namespace 안에서 수행한 마운트는 호스트 OS나 다른 namespace에 액세스 할 수 없다
UTS namespace : namespace별로 호스트명이나 도메인명을 독자적으로 가질 수 있다
IPC namespace : 프로세스 간의 통신(IPC - Inter-Process Communication - 공유 메모리, 세마포어/메시지 큐) 오브젝트를 namespace별로 독립적으로 가질 수 있다 ( 세마포어 - Semaphore - 자원관리에 이용되는 배타 제어장치 - 공유 자원의 개수 변수)
릴리즈 관리 장치 - cgroups - Docker는 물리 머신 상의 자원을 여러 컨테이너가 공유하며 작동함 이때 Linux kernel 기능인 control grouos 기능을 사용하여 자원의 할당 등을 관리함
cgroups는 프로세스와 스레드를 그룹화하여 그 그룹 안에 존재하는 프로세스와 스레드에 대한 관리를 수행하기 위한 기능 - 호스트 OS의 CPU나 메모리와 같은 자원에 대해 그룹별로 제한을 둘 수 있음 - cgroups로 컨테이너 안의 프로세스에 대해 자원을 제한함으로써 예를 들면 어떤 컨테이너가 호스트 OS의 자원을 모두 사용해 버려서 동일한 호스트 OS상에서 가동되는 다른 컨테이너에 영향을 주는 일을 막을 수 있다 - 관리 가능한 영역 : 1. cpu : CPU 사용량 제한 2. cpuacct : CPU 사용량 통계 정보를 제공 3. cpuset : CPU나 메모리 배치를 제어 4. memory : 메모리나 스왑 사용량을 제한 5. devices : 디바이스에 대한 액세스 허가/ 거부 6. freezer : 그룹에 속한 프로세스 정지/재개 7. net_cls : 네트워크 제어 태그를 부가 8. blkio : 블록 디바이스 입출력량 제어
cgroups는 부모 자식 관계에서는 자식이 부모의 제한을 물려받는다 - 자식이 부모의 제한을 초과하는 설정을 하더라도 부모 cgroups의 제한에 걸린다
네트워크 구성 - Linux는 Docker를 설치하면 서버의 물리 NIC가 docker0이라는 가상 브리지 네트워크로 연결된다 - 컨테이너가 실행되면 172,17.0.0/16이라는 서브넷 마스크를 가진 private IP 주소가 eth0로 자동으로 할당된다 OSI 2 계층인 네트워크 인터페이스로 pair인 NIC와 터널링 통신을 한다 - docker0이라는 가상 브리지 네트워크와 호스트 OS의 물리 NIC에서 패킷을 전송할 때는 NAPT기능을 사용한다
NAPT - Network Address Port Translation - 하나의 IP주소를 여러 컴퓨터가 공유하는 기술 - IP주소와 포트 번호를 변환하는 기능 - TCP/IP의 포트 번호까지 동적으로 변환하기 때문에 하나의 글로벌 IP 주소로 여러 대의 머신이 동시에 연결할 수 있다 - Docker에서는 NAPT에 Linux의 iptables를 사용한다
NAT(Network Address Translation)와 NAPT의 차이점 - NAT라우터는 클라이언트의 private IP를 NAT가 가지고 있는 public IP로 변환하여 요청을 송신한다 응답은 NAT라우터가 송신처를 클라이언트의 private IP 주소로 변환하여 송신한다 - 이러한 주소 변환은 public IP와 private IP를 1:1로 변환하기 때문에 동시에 여러 클라이언트가 액세스 할 수 없다 - NAPT는 private IP와 함께 포트 번호도 같이 변환한다 - private IP를 public IP로 변환할 때 private IP 별로 서로 다른 public IP:포트번호로 변환한다 - 201.xxx.xxx.xxx:1500 = A 가상 머신 , 201.xxx.xxx.xxx:1600 = B 가상 머신 - 이로써 하나의 public IP와 여러 개의 private IP를 변환할 수 있다 - Linux에서 NAPT를 구축하는 것을 IP Masquerade라고 부른다
Docker 이미지의 데이터 관리 장치 - 어떤 데이터를 복사할 필요가 생겼을 때 새로운 빈 영역을 확보하고 거기에 복사를 한다 하지만 만일 복사한 데이터에 변경이 없다면 A=B이면 그 복사는 쓸데없는 것이 된다 그래서 복사를 요구받아도 바로 복사하지 않고 원래의 데이터를 그대로 참조시켜 원본 또는 복사 어느 쪽에 수정이 가해진 시점에 비로소 새로운 빈 영역을 확보하고 데이터를 복사한다 이러한 장치를 Copy on Write라고 부른다 Docker에서는 Copy on Write 방식으로 컨테이너의 이미지를 관리한다 - Docker의 이미지를 관리하는 스토리지 디바이스로는 다음과 같은 것이 있다 1. AUFS : 다른 파일 시스템의 파일이나 디렉터리를 투과적으로 겹쳐서 하나의 파일 트리 구성, 표준 Linux kernel 아님 2. Btrfs : Linux용 Copy on Write 파일 시스템 - 롤백, snapshot 기능 3. Device Mapper : 파일 시스템의 블록 I/O와 디바이스의 mapping관계를 관리 - thin-provisioning, snapshot - Red Hat OS나 Ubuntu 등에서 Docker를 이용할 때 사용 4. OverlayFS : 파일 시스템에 다른 파일 시스템을 투과적으로 merging 하는 기능 5. ZFS : 볼륨 관리, snapshot, check sum, replication 등을 지원
위의 개념들은 추후 각 기능을 사용할 때 어떤 방식으로 컨테이너가 생성되는지를 이해하기 위해 필요하다
이제는 소프트웨어 엔지니어 또한 docker를 이용하여 실제 환경과 Test환경을 똑같게 만들어 작업을 한다
지금까지 docker를 사용해 왔지만 자세하고 세부적인 내용은 공부하지 않았다.
docker를 자세히 파악하여 더욱 다양한 방식으로 사용하기 위해 공부를 하자
1. 시스템 기반의 구성 요소
하드웨어 : 시스템 기반을 구성하는 물리적인 요소 (전원장치, 스토리지, 건물, 공조, 보안 설비, 소화 설비)
네트워크 : 시스템 이용자가 원격지에서 엑세스 할 수 있도록 서버들을 연결하기 위한 요구사항(라우터, 스위치,)
OS : 하드웨어나 네트워크 장비를 제어하기 위한 기본 소프트웨어(Windows, Ubuntu, CentOS)
하드웨어 리소스나 프로세스를 관리
서버용 OS도 존재 - 장시간 가동해도 안정적, 대량의 데이터 효율적 수행
미들웨어 :서버가 특정 역할을 다하기 위한 기능을 갖고 있는 소프트웨어(MySQL, NGINX, DB)
2. 시스템의 이용 형태
온프레미스(On-premises) : 자사에서 데이터센터를 보유하고 시스템 구축부터 운용까지를 모두 수행하는 형태
퍼블릭 클라우드 : 인터넷을 경우하여 불특정 다수에게 제공되는 클라우드 서비스
프라이빗 클라우드 : 특정 기업 그룹에게만 제공되는 클라우드 서비스
트래픽의 변동이 많거나 백업을 반드시 해야하는 시스템의 경우 클라우드를 이용하여 확장성을 확보할 수 있다
클라우드를 이용하면 비즈니스의 설립부터 서비스까지 릴리즈 시간을 줄일 수 있다.
3. Linux
linux kernel : OS의 코어가 되는 부분, 메모리 관리, 파일 시스템, 프로세스 관리, 디바이스 제어 등 OS로서 하드웨어나 어플리케이션 소프트웨어를 제어하기 위한 기본적 기장을 잦고 있는 소프트웨어
디바이스 관리 : 디바이스 드라이버라는 소프트웨어를 이용하여 하드웨어 제어
프로세스 관리 : 명령을 실행할 때 해당 프로그램 파일에 쓰여 있는 내용을 읽어 들여 메모리상에 전개한 후 메모리상의 프로그램을 실행함 = 프로세스
메모리 관리 : 프로그램과 데이터를 물리 메모리에 효율적으로 할당 - 메모리의 제한이 있으므로 하드디스크와 같은 보조기억장치에 가상 메모리 영역을 생성 = Swap memory - 메모리상에 전개된 이용 빈도가 낮은 데이터를 Swap으로 보내고 Swap상의 데이터를 다시 메모리로 돌림
Shell : 사용자가 내린 명령을 커맨드로 받아 kernel에 전달(bash, csh, tcsh, zsh) - 어플리케이션 실행, 정지, 재실행 - 환경변수 관리 - 명령 히스토리 관리 - 명령 실행 결과 표시 및 파일 출력
파일 시스템 : VFS(Virtual File System)라는 장치를 사용하여 데이터가 어디에 있던(하드, USB, network) 사용 가능
Linux distribution( 리눅스 배포판) : 보통 Linux는 배포판이라는 형태로 패키지화 되어 배포됨 ( Ubuntu, Debian, Fedora, CentOS)
Linux 파일 구성
/bin
기본 커맨드 ( ls, cp. mv 등 )
/boot
OS 시작에 필요한 파일 (커널이 해당 폴더의 vmlinuz라는 파일이다)
/dev
디바이스 파일 ( /dev/had = 하드 , /dev/ttf = 표준입출력이 되는 단말 디바이스)
/etc
설정 파일 ( IP, 사용자 비밀번호)
/home
사용자 홈 디렉토리
/lib
공유 라이브러리
/mnt
파일 시스템의 마운트 포인트용 디렉토리
/media
CD/DVD-ROM의 마운트 포인트
/opt
어플리케이션 소프트웨어 패키지
/proc
커널이나 프로세스에 관한 정보 (해당 폴더 아래있는 숫자 폴더는 프로세스ID를 뜻함, cpuinfo = CPU 정보, partitions = 디스크 파티션 정보)
/root
root용 홈 디렉토리
/sbin
시스템 관리용 마운트
/srv
시스템 교유의 데이터
/tmp
임시 디렉토리
/usr
각종 프로그램이나 커널 소스를 놓아두는 디렉토리
/var
로그나 메일 등 가변적인 파일을 놓아두는 디렉토리 ( /var/log = 가동 로그, /var/spool = 어플리케이션 임시 파일로 사용하는 스풀이 저장)
4. IaC (Infrastructure as Code)
Immitable Infrastructure : 클라우드를 이용함으로써 논리적으로 인프라를 재구성 할 수 있기 때문에 인프라의 변경 이력을 관리할 필요가 줄어듬 - 지금 있는것만 확인하면 됨
기존에는 파라미터 시트(버전 정보와 설정 항목의 설정 값이 쓰여있는 시트)를 토대로 수동으로 작업했지만 code를 이용하여 자동화 할 수 있다
Continuous integration : Code로써 인프라를 관리하기 때문에 Git등의 CI툴을 이용하여 인프라의 구조를 협업하기 편함( commit message, docker file)
5. 인프라 구성 관리 툴
OS의 시작을 자동화 : Red Hat 계열에서 사용가능한 KickStart, Local PC에 가상환경을 만들기 위한 Vagrant
OS나 미들웨어의 설정을 자동화 : DB server, web server, 감시 에이전트 등과 같은 미들웨어의 설치나 버전 관리, OS의 /etc 아래있는 설정 파일이나 방화벽 설정 자동화 - Chef, Ansible, Itamae, Puppet
여러 서버를 관리하는 자동화 : 컨테이너 오케스트레이션의 사실상 표준이 된 Kubernetes
CI(Continuous Integration) : 코드를 추가 및 수정할 때마다 테스트를 실행하여 확실하게 작동하는 코드를 유지하는 방법, 사양서에 정해진 대로 작동하는지를 확인 - Jenkins, Git
CD(Continuous Deploy) : 지속적 배포 - 기능을 추가할 때마다 어플리케이션을 제품 환경에 배포 - 배포에서 가장 중요한 점은 서비스의 연속성이다 서비스가 중지되면 안된다 - Blue Green deploy - 버전1서버을 블루 버전2서버를 그린라고 했을 때 블루를 서비스하면서 그린을 테스트하여 성공하면 그린을 서비스하고 블루를 종료 - 자연스러운 변경이지만 클라우드 환경이 아니라면 어려움