최신 SOTA 모델인 YOLOX 논문이다
기존 누구나 생각했던 YOLO의 문제점? 불편함이었던 사항들을 전부 수정한듯한 느낌이다
기존 불편한점 : Anchor based model , Anchor 최적, ancho는 그저 mAP를 끌어올리기 위한 수단, 과연 coupled head는 regression loss와 classification loss, obj loss 중 어떤 게 더 많이 잘못됐는지 알고 있을까? end-to-end 학습을 위해 NMS를 없애고 싶다

Abstract
- 기존의 YOLO 시리즈를 anchor-free로 변경하고 다른 디텍션 테크닉을 사용
- Decoupled head
- Leading label assignment strategy - SimOTA
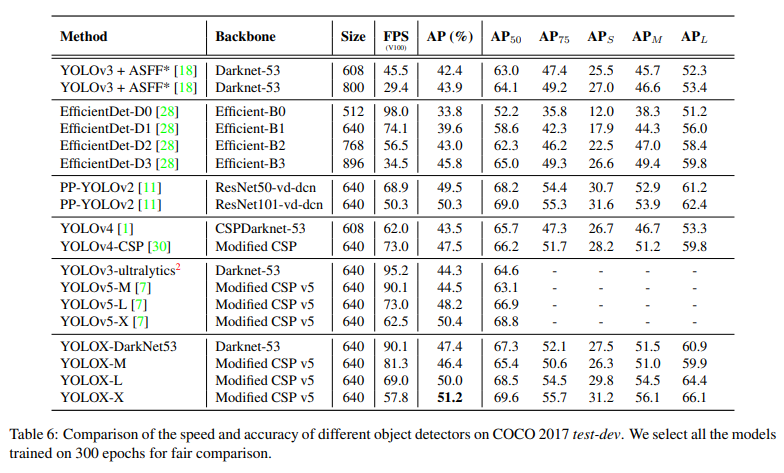
- COCO 데이터셋에서 기존보다 3%정도 뛰어난 47.3%의 AP를 얻음
Introduction
- 지난 2년간 객체인식 분야의 주된 관점은 anchor-free detectors와 end-to-end(NMS-free) detectors이다. 이런 기술들은 아직 YOLO시리즈에 접목되지 않았고 SOTA였던 YOLOv4와 YOLOv5 또한 anchor-based detector이어서 학습 시 hand-craft로 하이퍼 파라미터들을 수정해야 했다
- 저자는 기존의 YOLOv4와 5는 anchor-based에 과하게 최적화 되어있어 YOLOv3을 베이스 모델로 선택하였다
YOLOX
- YOLOX-DarkNet53
- YOLOv3 + DarkNet53을 베이스 라인으로 사용
- 300 epochs 학습 진행, 5 epochs는 COCO train2017로 warm-up 진행
- SGD momentum 0.9 사용
- Learning rate는 lr X BatchSize/64 ( linear scaling ), 초기 lr = 0.01
- cosine scheduler 사용
- weight decay 0.0005
- batch size 128 ( 8-GPU)
- Input size = 448 ~ 832 ( 32 strides)
- 모든 실험 FPS, latency는 모두 FP-16, batchsize 1 , Tesla V100으로 진행
- YOLOv3 baseline
- DarkNet53, SPP layer ( YOLOv3-SPP)
- 추가로 EMA weights updating 사용 ( EMA : Exponential Moving Average)
- Cosine lr schedule
- IoU loss, IoU-aware branch
- 학습때regression 브런치에 대해 IoU loss를 사용한 것이 큰 성능 향상을 불러왔다 한다
- Augmentations
- RamdomHorizontalFlip
- ColorJitter
- Multi-scale for data augmentation
- Random Resized Crop은 Mosaic과 상충한다 생각되어 사용하지 않음
- Decoupled head
- 기존 객체인식에서 분류와 회귀의 잘 알려진 conflict가 있었다. 대부분의 decoupled head는 one-stage, two-stage에서 많이 사용되었지만 YOLO시리즈는 백본 및 feature pyramids가 지속적으로 변함에 따라 detection head는 coupled로 유지되었다
- 저자는 두가지 분석 실험을 통해 coupled detection head는 성능에 문제가 있단 걸 알았다
- YOLO의 head를 decoupled 로 변경하니 높은 성능 향상이 있었다
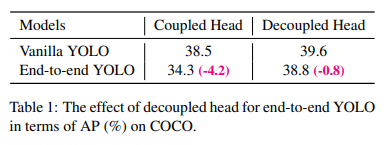
또한 decoupled head는 end-to-end 학습에 필수적이다 - Coupled head와 decoupled head를 비교한 결과 Coupled head에서는 4.2%의 성능 감소가 있었고 decoupled head에서는 0.8%의 성능 감소가 있어 YOLO detect head를 가벼운(lite) decoupled head로 대체하였다
- 구체적으로 1x1 conv로 채널차원을 감소시키고 각각 두 개의 병렬 3x3 conv가 따른다

- Strong data augmentation
- Mosaic과 MixUp 이용 – YOLOX의 성능을 boost함
- MixUp은 classification을 위해 design됐지만 객체 검출 학습에서 BoF(Bag of Freebies)로 수정되었다
- MixUp과 Mosaic을 모델에 적용했고 마지막 15epochs에서는 close 하였다
- Data augmentation을 사용한 후 ImageNet pre-training은 더 이상 효과를 보지 못했다 – 그래서 뒤의 모든 학습은 스크레치부터 학습하였다
- Anchor-free
- 기존의 YOLOv4, v5는 anchor-base 파이프라인으로 엥커 메커니즘은 많은 문제들이 있었다
1. 검출 성능을 최적화하기 위해서는 엥커의 크기를 찾기 위해 클러스트링을 진행해야 한다. 이런 클러스트링은 학습 때마다 도메인을 특정(domain-specific)하게 되고 일반화에 좋지 않다
2. anchor 메커니즘은 detection head의 복잡도와 이미지마다 예측하는 숫자를 증가시킨다. 이러한 메커니즘은 edge AI system에서 병목현상을 야기한다 - Anchor-free detector는 디자인 파라미터의 수를 감소시키고 heuristic한 튜닝과 많은 트릭들(clustering, grid sensitive)이 필요하지 않게 된다
- 기존의 YOLO를 anchor-free로 변경하는 것은 그렇게 어렵지 않다
각 로케이션마다 3개씩 예측하던 것을 1개로 변경하고 직접 4개의 값을 예측하도록 하였다 (left-top corner, height, width) - location of each object as the positive sample and pre-define a scale range, as done in [29], to designate the FPN level for each object. – 이러한 수정이 파라미터와 GFLOPs를 감소시키고 성능을 증가시켰다
- 기존의 YOLOv4, v5는 anchor-base 파이프라인으로 엥커 메커니즘은 많은 문제들이 있었다
- Multi positives
- 기존 YOLOv3의 할당 rule과 같게 anchor-free 버전 또한 하나의 positive sample을 할당하였다 ( 각 예측에 대해 다른 비슷하게 잘 예측한 예측은 무시)
하지만 이러한 좋은 (할당하지 않는) 예측들은 가중치 update에 좋은 이득을 가져온다
이러한 좋은 예측은 positive와 negetive와의 극심한 불균형을 완화시킨다
저자는 간단하게 center에서 3x3 area를 positives로 정했다 – 이름은 center sampling이라고 했다 - 결과적으로 45%로 성능이 향상됐고 ultralytics(YOLOv5 저자)의 yolov3의 성능을 이미 넘었다
- 기존 YOLOv3의 할당 rule과 같게 anchor-free 버전 또한 하나의 positive sample을 할당하였다 ( 각 예측에 대해 다른 비슷하게 잘 예측한 예측은 무시)
- SimOTA
- Advanced label assignmetn는 객체 검출에 중요한 과정이다. 기존 저자의 연구인 OTA를 기준으로 4가지 insights를 정했다
1. Loss/Quality aware
2. Center prior
3. Dynamic number of positive anchors for each ground-truth
4. Global view - 특히 OTA는 레이블 할당에 global 관점을 가지게 한다 - Optimal transport problem을 공식화할 수 있게 한다
- 저자는 Sinkhorn-Knopp algorithm을 이용하여 OT problem을 해결한다.
하지만 25%의 추가적인 학습 시간이 필요하다
이것은 quite expensive 하기 때문에 OT(Optimal transport)를 간단히 한 SimOTA를 제안한다 - Dynamic top-k starategy를 사용한다
- SimOTA는 먼저 각 예측-GT 쌍에 대해 cost 또는 quality로 표시되는 pair 매칭 정도를 계산한다
- Gt gi와 prediction pj와의 cost 계산은 다음과 같다 cij=Lijcls+λLijreg
λ는 balancing coefficient
Lijcls와 Lijreg는 gt와 predictions의 classification loss와 regression loss를 뜻한다
그러고 나서 gt에 대해서 고정 중앙 영역 내에서 비용이 가장 적게 드는 Top-k 예측을 positive sample로 선택한다
마지막으로 이러한 positive prediction의 해당 grid는 positive로 할당된다
k 값은 gt의 개수에 따라 다른 값을 가진다 - SimOTA는 학습 시간만 감소시키는 것이 아닌 Simkhorn-Knopp algorithm의 solver 하이퍼파라미터들을 방지한다
- Advanced label assignmetn는 객체 검출에 중요한 과정이다. 기존 저자의 연구인 OTA를 기준으로 4가지 insights를 정했다

- End-to-End YOLO
- (Qiang Zhou, Chaohui Yu, Chunhua Shen, Zhibin Wang, and Hao Li. Object detection made simpler by eliminating heuristic nms. arXiv preprint arXiv:2101.11782, 2021)를 따라 두 개의 추가적인 conv, one-to-one label assignment, stop gradient를 추가한다
- 이러한 적용은 end-to-end 학습이 가능하게 하지만 약간의 성능 감소와 추론 속도 추가를 발생시킨다
- (Qiang Zhou, Chaohui Yu, Chunhua Shen, Zhibin Wang, and Hao Li. Object detection made simpler by eliminating heuristic nms. arXiv preprint arXiv:2101.11782, 2021)를 따라 두 개의 추가적인 conv, one-to-one label assignment, stop gradient를 추가한다

- Model size and data augmentation
- 대부분의 모델에서 같은 룰을 적용했지만 augmentation 전략에서는 모델의 사이즈에 따라 몇 개의 차이가 있다
- 작은 모델의 경우(YOLOX-nano) 강한 data augmentation은 성능 감소가 따랐다 그렇기 때문에 MixUP의 경우 삭제하고 mosaic의 경우 scale range를 감소시켰다 [0.1,2.0] 🡪 [0.5,1.5]
- 하지만 큰 모델의 경우 강한 augmentation이 성능 증가가 따랐다
MixUP의 경우 기존의 버전보다 더 강하게 적용하였고
Copypaste에서 영감을 받아 두 이미지를 혼합하기 전에 무작위로 샘플링된 scale factor로 두 이미지를 jittered 하였다
MixUP에서 Scale jittering의 효과를 비교하기 위해 COPYpaste(YOLOX-L)와 비교하였다 ( Copypaste는 instance mask(segmentation)가 필요하지만 MixUP은 필요하지 않다)