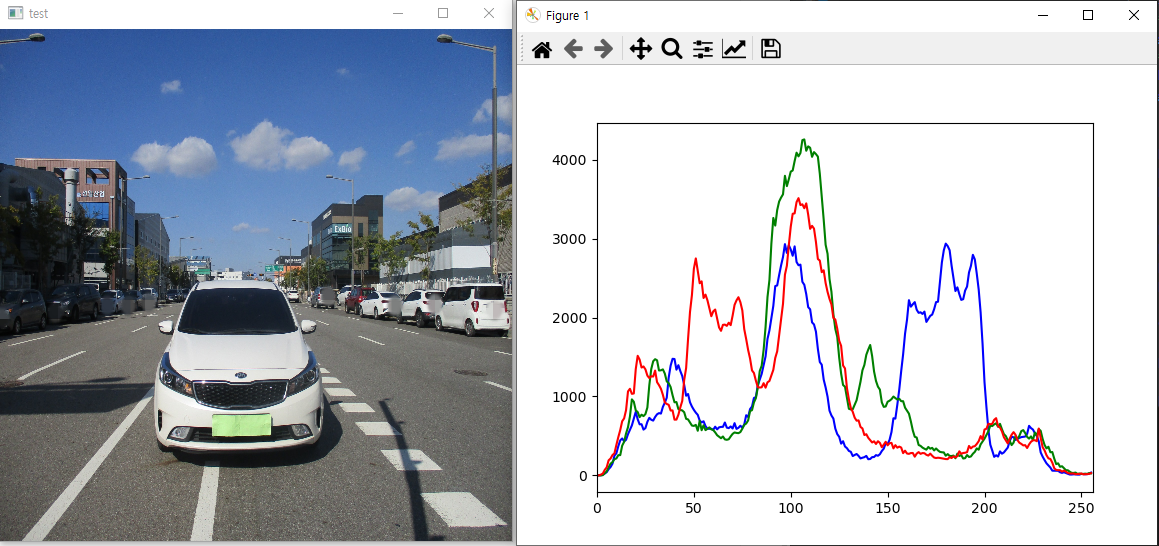
이전 장에서 학습한 2D histogram 분석을 이용해 여러 label 데이터의 분석을 진행하겠다
1. image data


- 위의 사진을 보면 가운데 차량과 가상에 주차되어있는 차량에 바운딩박스가 쳐져 있다
- 이 데이터를 가지고 각 각 바운딩 박스가 쳐져 있는 차량들의 2D histogram을 생성하여 어떤 분포를 가지고 있는지 비교하여 보겠다
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('test.JPG')
# hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h,w,_ = image.shape
box_list = []
mask_image = []
temp_image = []
seed = 8
with open('test.txt','r') as rd:
boxes = rd.readlines()
for box in boxes:
box = box.strip()
box = box.split()
box = list(map(float,box))
box_width = box[3] * w
box_height = box[4] * h
box_center_x = box[1] * w
box_center_y = box[2] * h
xmin = int(box_center_x - box_width/2)
ymin = int(box_center_y - box_height/2)
xmax = int(box_center_x + box_width/2)
ymax = int(box_center_y + box_height/2)
mask = np.zeros((h,w), np.uint8)
mask[ymin:ymax, xmin:xmax] = 255
mask_image.append( cv2.resize(image[ymin:ymax,xmin:xmax],(300,300)))
for i in range(seed,len(mask_image)):
if i == seed:
temp_image = mask_image[i]
else:
temp_image = np.concatenate((temp_image,mask_image[i]), axis=1)
cv2.imshow('bounding boxes',temp_image)
cv2.waitKey(0)
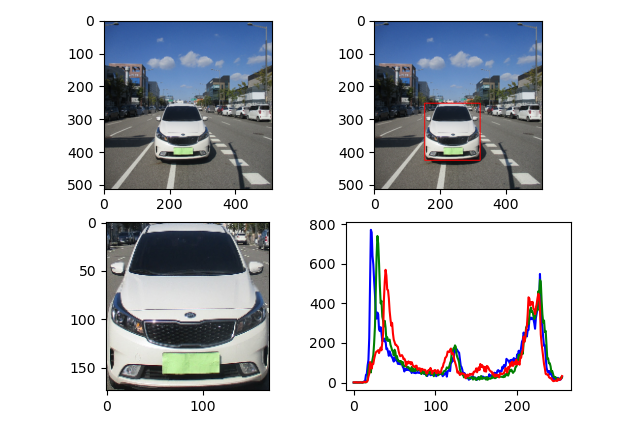
- 바운딩박스 영역의 객체들을 잘라내어 표시해 보았다
- resize를 하여 2D histogram에 같은 비율로 적용이 되도록 하였다
- 처음 알았는데 opencv imshow는 사용자의 해상도에 맞춰 이미지를 최대 해상도 까지만 표현한다
2. cv2.compareHist(hist1, hist2, method)
- hist1 과 hist2 는 서로 비교할 histogram을 넣는다
- method는 https://docs.opencv.org/3.4/d8/dc8/tutorial_histogram_comparison.html 에 공식까지 잘 나와있다
cv2.HISTCMP_CORREL : 두 히스토그램의 상관관계를 분석한다
cv2.COMP_CHISQR : 카이제곱검정으로 분석한다
cv2.COMP_INTERSECT : Intersection
cv2.COMP_BHATTACHARYYA : bhattacharyya distance - 바타챠랴 거리 측정법으로 분석한다 hellinger distance와 같다
cv2.COMP_KL_DIV : Kullback-leibler divergence - 쿨백-라이블러 발산으로 확률분포의 차이를 계산한다
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('test.JPG')
# hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h,w,_ = image.shape
mask_image = []
hist_list = []
with open('test.txt','r') as rd:
boxes = rd.readlines()
for i, box in enumerate(boxes[10:15]):
box = box.strip()
box = box.split()
box = list(map(float,box))
box_width = box[3] * w
box_height = box[4] * h
box_center_x = box[1] * w
box_center_y = box[2] * h
xmin = int(box_center_x - box_width/2)
ymin = int(box_center_y - box_height/2)
xmax = int(box_center_x + box_width/2)
ymax = int(box_center_y + box_height/2)
mask = np.zeros((h,w), np.uint8)
mask[ymin:ymax, xmin:xmax] = 255
add_image = cv2.resize(image[ymin:ymax,xmin:xmax], (200,200))
cv2.imshow(str(i),add_image)
add_image = cv2.cvtColor(add_image, cv2.COLOR_BGR2HSV)
hsv_hist = cv2.calcHist([add_image],[0,1],None,[360,256],[0,360,0,256])
cv2.normalize(hsv_hist,hsv_hist,0,1, cv2.NORM_MINMAX)
hist_list.append(hsv_hist)
# cv2.compareHist
for i,hist1 in enumerate(hist_list):
for j, hist2 in enumerate(hist_list):
ret1 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_CORREL)
ret2 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_CHISQR)
ret3 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_INTERSECT)
ret4 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_BHATTACHARYYA)
ret5 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_HELLINGER)
ret6 = cv2.compareHist(hist1,hist2, cv2.HISTCMP_KL_DIV)
print("\t\t\t\t\t\t\t{} 번과 {} 번의 비교".format(i,j))
print("-------------------------------------------------------------------------------------------------------------------------------------------")
print(" 상관관계 : {:.4f} \t 카이제곱 : {:.4f} \t 인터섹션 : {:.4f} \t 바타챠랴 : {:.4f} \t 헬링거 : {:.4f} \t 콜백발산 : {:.4f} ".format(
ret1,ret2,ret3,ret4,ret5,ret6
))
print("-------------------------------------------------------------------------------------------------------------------------------------------")
cv2.waitKey(0)
- calcHist로 계산한 결과를 normalize하여 0과 1의 값으로 보기 좋게 하였다
- 바타챠랴 거리와 헬링거는 같은 함수이다
https://github.com/dldidfh/tistory_code/tree/master/multi%20image%20histogram
GitHub - dldidfh/tistory_code
Contribute to dldidfh/tistory_code development by creating an account on GitHub.
github.com
'Machine Learning > Computer Vision' 카테고리의 다른 글
| (8) OpenCV python - 차영상 기법, background subtraction(배경 추출) (2) | 2021.08.16 |
|---|---|
| (7) OpenCV python - Erosion(침식), Dilation(확장), Opening, Closing 이미지 변환 기초, 이미지 잘라내기 (0) | 2021.08.11 |
| (5) OpenCV python - 2D Histogram 분석 (0) | 2021.07.29 |
| (4) OpenCV python - 이미지 데이터 분석 HSV format, 이미지 값 조절 (0) | 2021.07.29 |
| (3) OpenCV python - Histogram 분석 calcHist() (0) | 2021.07.27 |