이번 장에서는 차영상기법이 사용되는 유용한 기법인 배경 추출에 대해서 알아보겠다
간단한 차영상부터 시작해서 OpenCV 함수 이용까지 다루어 보겠다
1. 차영상 기법
- 차영상이란 어느 한 이미지와 다른 이미지와의 차이를 나타낸다
- Image subtraction과 pixel subtraction이 대표적이다
- 하나의 영상에서 첫 번째 프레임과 다음 프레임의 pixel 기준 차이를 생성해보겠다

import cv2
import time
import numpy as np
from numpy.lib.function_base import diff
video_path = './cctv.mp4'
output_path = './background_extraction_output.mp4'
video = cv2.VideoCapture(video_path)
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 프레임 정보를 저장해놓을 변수를 선언한다
first_frame = np.zeros((400,400,3))
second_frame = np.zeros((400,400,3))
# 영상에서 첫 프레임과 두번째 프레임을 저장한다
for i in range(2):
return_value, frame = video.read()
frame = cv2.resize(frame,(400,400))
if i == 0 : first_frame = frame
if i == 1 : second_frame = frame
diff_image = second_frame - first_frame
concat_image = np.concatenate((first_frame,second_frame,diff_image),axis=1)
cv2.imshow('images',concat_image)
cv2.waitKey(0)- 위의 사진과 같이 하나의 고정된 영상장치에서 프레임간의 차이는 움직이는 객체를 표현하기 좋다
- 배경은 움직이지 않고 가만히 있다 보니 배경이 없어지고 움직이는 자동차에 대해서 픽셀의 값이 높게 나오는 것을 볼 수 있다
- 위의 예제는 3채널(BGR)의 차이를 보이다 보니 먼가 고장 난 TV처럼 보인다.
- GRAY scale로 변환한 뒤 다시 확인해보자

- BGR보다는 더 보기 편해 보인다 하지만 눈으로 보기에 무엇인가 깔끔하지 않다.
- 깔끔하지 않기에 깔끔하게 만들기 위해서는 전에 (7)장에서 학습한 Opening과 closing을 이용할 수 있지만 opencv에서는 여러 가지 함수를 이용해 더욱 깨끗한 차영상을 만들 수 있다
2. opencv- createBackgroundSubtraction - 배경분리

import cv2
import numpy as np
import time
video_path = './cctv.mp4'
output_path = './background_subtraction_output.mp4'
video = cv2.VideoCapture(video_path)
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(video.get(cv2.CAP_PROP_FPS))
codec = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, codec, fps, (width, height))
fgbg = cv2.createBackgroundSubtractorKNN(detectShadows=False)
# fgbg = cv2.bgsegm.createBackgroundSubtractorMOG(history=200,nmixtures=3,backgroundRatio=0.7, noiseSigma=0)
# fgbg = cv2.createBackgroundSubtractorMOG2(history=200,varThreshold=32,detectShadows=False)
# fgbg = cv2.bgsegm.createBackgroundSubtractorGMG(initializationFrames=20, decisionThreshold=0.5)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(7,7))
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7))
while(1):
start = time.time()
return_value, frame = video.read()
# 비디오 프레임 정보가 있으면 계속 진행
if return_value:
pass
else :
print('비디오가 끝났거나 오류가 있습니다')
break
background_extraction_mask = fgbg.apply(frame)
# background_extraction_mask = cv2.morphologyEx(background_extraction_mask,
# cv2.MORPH_CLOSE, kernel)
background_extraction_mask = cv2.dilate(background_extraction_mask,kernel,iterations=1)
background_extraction_mask = np.stack((background_extraction_mask,)*3, axis=-1)
concat_image = np.concatenate((frame,background_extraction_mask), axis=1)
cv2.imshow('background extraction video', concat_image)
cv2.waitKey(0)
video.release()
cv2.destroyAllWindows()- opencv python 기본 패키지에는 MOG와 GMG가 없다 pip install opencv-contrib-python 가 필요하다
- 우선 opencv에서 비디오를 읽어와 변환한 영상을 다시 저장할 때는 위의 예처럼 읽어온 video에서 영상의 해상도(height, width)를 불러오고 영상의 FPS, codec정보를 불러와 저장할 영상의 정보를 설정해 줘야 한다 ( 기존 영상의 FPS가 30이고 새로운 영상의 FPS를 10으로 설정하면 3배 빠르게 움직이고 영상의 길이가 길어진 것을 볼 수 있을 것이다)
- cv2.createBackgroundSubtractor XXX
- 배경추출을 진행할 함수를 선언해준다 종류로는 MOG, MOG2, KNN, GMG 가있다.
- 각각의 알고리즘에 대한 세부적인 내용은 구글링을 통해 학습하는 것이 좋을 것이다.
- MOG - Mixture of Gaussian - Gaussian Mixture Model - K개의 Gaussian model의 결합
- MOG2 - Adaptive Mixture of Gaussian - 픽셀에 대해 적절한 수의 Gaussian distribution을 선택
- KNN - K-Nearest Neighbor 최근접이웃 알고리즘
- GMG - Bayesian과 Kalmanfilter의 조합
- MOG와 GMG의 경우 현재 버전의 opencv 기본 패키지에서는 존재하지 않는다. 대부분 MOG2를 사용하는데 성능이 MOG와 GMG에 비해 좋아서 삭제한 거 같다
- KNN과 MOG중 자신이 하려는 부분에 맞는 알고리즘을 사용하는 것이 좋다. 이번 글에서는 KNN을 이용하였다
- KNN의 결과물에 dilate를 하여 움직이는 객체의 안쪽 부분의 noise를 줄였다 ( 객체 주변의 배경에 대한 노이즈가 늘어난다 일반적으로 dilate보단 opening과 closing을 추천한다 )
3. 원본 영상에 mask 적용 cv2.bitwise_and(src1, src2)
- 위의 사진에서 KNN의 결괏값으로 나온 흑백으로는 실제 해당 위치에 어떤 객체가 있는지 판단하기 어렵다(classification) 그렇기에 실제 영상에 마스크를 적용하여 classification에 적용하기 좋은 영상으로 만들어보자
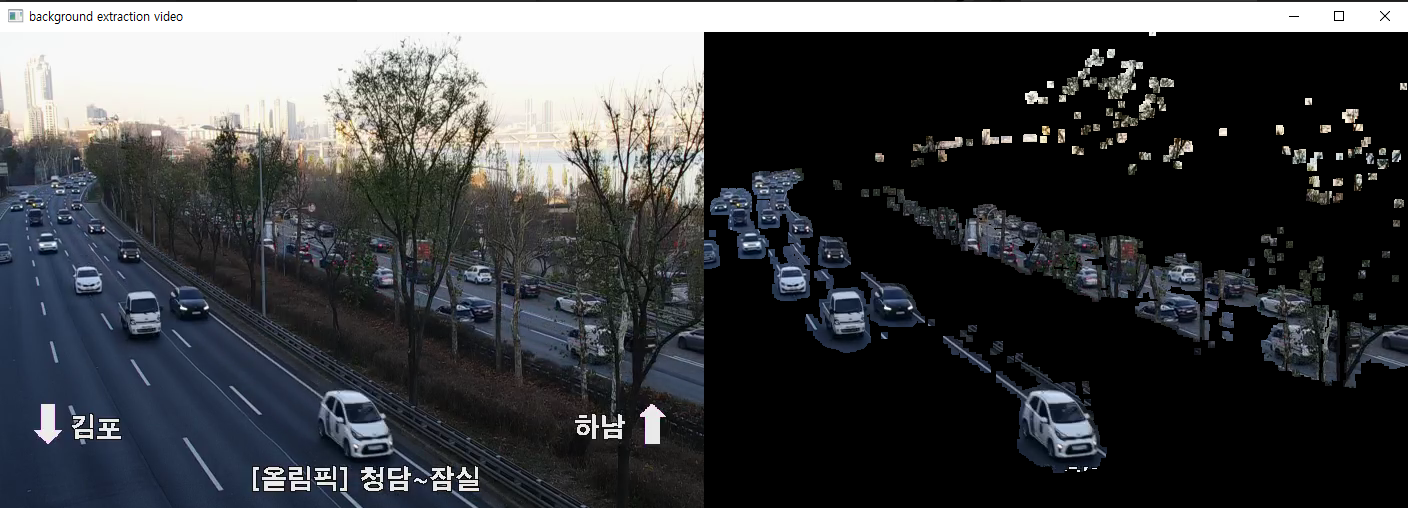
import cv2
import numpy as np
import os
import time
video_path = './cctv.mp4'
output_path = './mask_background_subtraction_output.mp4'
video = cv2.VideoCapture(video_path)
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(video.get(cv2.CAP_PROP_FPS))
codec = cv2.VideoWriter_fourcc(*'mp4v')
# codec = int(video.get(cv2.CAP_PROP_FOURCC))
print(codec, type(codec))
# # # codec = chr(codec&0xff) + chr((codec>>8)&0xff) + chr((codec>>16)&0xff) + chr((codec>>24)&0xff)
# # # codec = cv2.VideoWriter_fourcc(*codec)
# # print(codec)
out = cv2.VideoWriter(output_path, codec, fps, (width, height))
fgbg = cv2.createBackgroundSubtractorKNN(detectShadows=False)
# fgbg = cv2.bgsegm.createBackgroundSubtractorMOG(history=200,nmixtures=3,backgroundRatio=0.7, noiseSigma=0)
# fgbg = cv2.createBackgroundSubtractorMOG2(history=200,varThreshold=32,detectShadows=False)
# fgbg = cv2.bgsegm.createBackgroundSubtractorGMG(initializationFrames=20, decisionThreshold=0.5)
# kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(7,7))
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7))
time_cost = 0
fps_cost = 0
frame_num = 0
while(1):
start = time.time()
frame_num +=1
return_value, frame = video.read()
# 비디오 프레임 정보가 있으면 계속 진행
if return_value:
pass
else :
print('비디오가 끝났거나 오류가 있습니다')
break
background_extraction_mask = fgbg.apply(frame)
# background_extraction_mask = cv2.morphologyEx(background_extraction_mask,
# cv2.MORPH_CLOSE, kernel)
background_extraction_mask = cv2.dilate(background_extraction_mask,kernel,iterations=1)
background_extraction_mask = np.stack((background_extraction_mask,)*3, axis=-1)
bitwise_image = cv2.bitwise_and(frame, background_extraction_mask)
concat_image = np.concatenate((frame,bitwise_image), axis=1)
time_temp = 1000*(time.time()-start)
if time.time()-start != 0.0:
fps_temp = 1/(time.time()-start)
else:
fps_temp=0.01
time_cost = time_cost + time_temp
fps_cost = fps_cost + fps_temp
print('소요 시간 : {:.2f} ms \t 평균FPS : {:.2f}'.format(time_temp,fps_temp))
cv2.imshow('background extraction video', concat_image)
cv2.waitKey(0)
print('소요시간 평균 : {:.2f} ms\t 평균FPS : {:.2f}'.format(time_cost / frame_num, fps_cost/ frame_num))
video.release()
cv2.destroyAllWindows()- 2. 의 코드에서 bitwise_and를 하는 항목과 소요된 시간을 체크하는 코드가 추가되었다
- bitwise_and는 두 데이터 간의 AND작업을 진행한다 (0 and 0 = 0) (1 and 0 = 0) (1 and 1 = 1)
- 기존의 영상은 3 채널 BGR이미지이기에 backgroundSubtraction의 결괏값에 np.stack을 이용하여 grayscale 2 채널 이미지를 3 채널로 만들어줬고 원본 영상과 3 채널이 된 배경추출 결괏값을 서로 and 해주었다
- 배경추출 결괏값에서 배경은 0으로 표현이 되고 움직이는 객체는 255로 표현이 되기에 서로를 and 하면 원본 영상에서 움직이는 객체만 표현할 수 있다
- 그런데 예를 들어 255와 120을 and 하면 0이 나와야 하는 거 아니냐?라는 생각이 들 수 있다. 여기서 0이 아닌 120이 나오는 이유는 bitwise에서 답을 찾을 수 있다
- bitwise는 bit의 기준에서 and를 한다 opencv는 기본적으로 uint8의 data type을 사용한다
- bit기준으로 255 = 11111111 120 = 01111000으로 표현된다 그러므로 서로 bitwise and를 하면 01111000이 되기 때문에 255 and 120의 bitwise and는 120이 된다
각 background subtraction을 자신이 하려는 작업에 맞게 사용하자 저자는 이미지에서 움직이는 객체를 표시하고 객체의 외곽선을 정확히 나눈다 보다는 객체의 내부에 noise를 지우기 위해 사용하였고 그렇기 때문에 배경에 대해서 noise가 늘어나는 것을 감수했다 또한 배경 추출의 처리속도를 고려하여 비교적 빠르고 내부 noise를 줄일 수 있는 KNN을 사용하였다.
외곽선에 대해서 더 정확하게 나누고 싶다면 GMG의 parameter에서 initializationFrames를 높여가며 테스트를 해보는 것도 좋을 것이다
https://github.com/dldidfh/tistory_code
GitHub - dldidfh/tistory_code
Contribute to dldidfh/tistory_code development by creating an account on GitHub.
github.com
'Machine Learning > Computer Vision' 카테고리의 다른 글
| (10) OpenCV python - 색상 범위 추출 - inRange (0) | 2021.11.27 |
|---|---|
| (9) OpenCV python - 마우스 동작 함수 - setMouseCallback (0) | 2021.11.21 |
| (7) OpenCV python - Erosion(침식), Dilation(확장), Opening, Closing 이미지 변환 기초, 이미지 잘라내기 (0) | 2021.08.11 |
| (6) OpenCV python - multi label Histogram 분석 (0) | 2021.07.30 |
| (5) OpenCV python - 2D Histogram 분석 (0) | 2021.07.29 |