기존 깊은 Convolution network의 vanishing gradient 문제는 Residual short cut을 통해 극복하였고 이제는 어떻게 하면 더 적은 파라미터로 좋은 성능을 낼 수 있는가가 되었다
이후로는 어떻게 이전 레이어의 정보를 다음 레이어에 효율적으로 전달할 수 있는가? 가 주된 관심사가 되었다
1. Abstract
- Cnn은 객체 인식 머신러닝에서 뛰어난 성과를 보였고 CNN에서 중요한 점은 네트워크의 깊이이다 LeNet부터 시작하여 Highway Networks, Residual Network들은 depth가 100이 넘게 레이어를 쌓았다
- CNN에서 네트워크가 점점 깊어지면서 생긴 문제점은 vanishing gradient와 washout이다. ResNet과 Highway Network는 Identity connection을 통하여 하나의 레이어에서 다음 레이어로 signal을 연결한다
- Stochastic depth shortens ResNet은 더 좋은 gradient flow를 위하여 학습중에 레이어를 무작위로 삭제하여 ResNet을 단축한다
- FractalNets은 네트워크에서 하나의 인풋에 대하여 여러 short paths로 나누어 Convolution을 적용하여 Residual을 학습하는 것과 비슷하게 네트워크를 깊게 쌓을 수 있
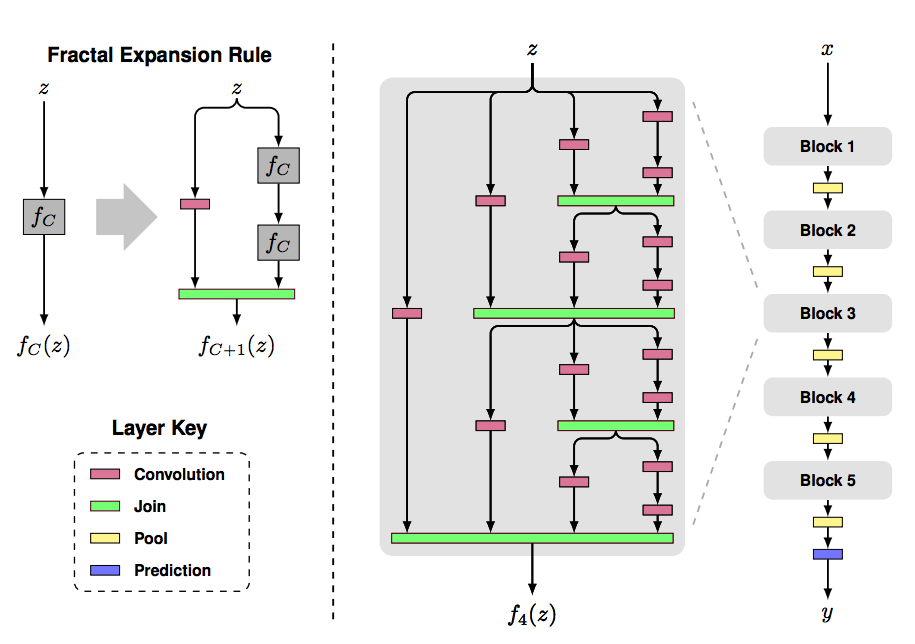
- 위에서 설명한 네트워크들은 다양한 네트워크 구조와 트레이닝 절차에 대하여 다양한 접근법을 제시하지만 모두 같은 요점이 있다 - short path로 이전 레이어와 이후 레이어를 연결한다는 점이다
- 저자의 제안은 위에서 제안한 방식들에서 좋은 점만 빼서 네트워크안 레이어 사이의 최대의 정보 흐름을 보장한다
- 직접적으로 서로 다른 레이어를 연결한다 (feature map size를 amtching 한다 )
- Feed-forward 특성을 유지하기 위해 각 레이어는 모든 이전 레이어에서 추가 입력을 얻고 모든 후속 레이어가 가진 feature-map을 전달한다
- ResNet과는 다르게 DenseNet은 Short cut을 summation하지 않고 concatenation 한다
- 이 연결패턴의 직관적이지 않는 부분은 기존 convolution net보다 더 적은 파라미터가 필요하다는 것이다 - 중복된 feature map을 다시 학습할 필요가 없기 때문에
- 각 계층은 이전 계층에서 상태를 읽고 후속 계층에 write 한다
상태를 변경도 하지만 보존해야 하는 정보도 전달한다 - DenseNet은 네트워크에 추가되는 정보와 이전 레이어의 정보를 명시적으로 구분한다
- DenseNet은 매우 narrow 하다 ( 레이어당 12개의 필터 )
- 각각의 레이어는 loss function과 원본 입력 signal의 gradients에 직접적으로 접근할 수 있다
또한 dense connection이 regularizing 효과도 있는 것을 관찰했다
overfitting을 감소시키고 학습 셋의 사이즈를 작게 가져갈 수 있다
2. DenseNet
- 기존의 ResNet의 공식은 \( x_L\) = \(H_L(x_L - 1) + x_L-_1) \) 이였다
- ResNet의 장점은 identity function을 통해 다음의 레이어에 이전 레이어의 가중치가 직접적으로 흐를 수 있다는 것이었다 하지만 여기서 identity function은 아웃풋 \(H_L\)은 summation울 포함하게 되는데 이는 정보의 흐름을 방해할 수 있다
- Dense Connectivity
- 1) 모든 이후 레이어에 이전의 모든 레이어를 직접적으로 연결한다

- 2) \(x_L = H_L([x_0, x_1, ... , X_L-_1]\)
- 위의 수식은 x들끼리의 feature map의 size가 같지 않으면 실행될 수 없다 하지만 convolution network에서 필수적인 부분은 downsampling(pooling 레이어)이다.
- pooling을 가능하게 하기 위해 densely 연결된 dense block을 나눈다 ( 위 사진에서 Dense Block 1, 2, 3 )
- 여기서 Dense Block 사이에 들어가는 Conv, Pooling을 transition layer라고 부르겠다 한다
- Batch norm과 1x1 conv, 2x2 avg pooling을 진행한다
- Growth rate
- 저자는 DenseNet에서 매우 narrow 한 레이어 구조를 갖기 위해 Growth rate라는 하이퍼파라미터를 추가하였다
- 해당 파라미터는 하나의 Dense Block을 지날 때마다 증가되는 feature map의 사이즈를 말한다
- 만약 \(H_L \) 이 k개의 feature map을 만든다면 다음 레이어는 \(k_0 + k x (L-1)\)의 input feature map을 가진다

- Bottleneck layers
- 각 레이어는 k개의 output feature-map을 가지지만 인풋은 더 크게 가질 수 있다
- 3x3 conv 이전에 1x1 conv를 이용하여 인풋 feature-maps의 개수를 줄일 수 있다 이는 또한 computational efficiency를 얻을 수 있다 - 이는 특히 narrow 한 DenseNet에 이점이 많다
- BN - ReLu - Conv(1x1) - BN - ReLu - Conv(3x3)
- 저자의 실험에 기반하여 각 1x1 conv가 4k의 feature-map을 생성하도록 한다
- Compression
- 모델의 compactness(소형화)를 더 향상하기 위해 transition layer에서 feature-map의 개수를 감소시킨다
- Transition layer는 \(\theta m\)개의 output feature-map을 갖는다 0 < \(\theta\) < 1
DenseNet-C는 \(\theta\)를 0.5로 하였다
- Implementation Details
- 3x3 Conv는 입력에 대해 동일한 크기의 feature-maps를 유지하기 위해 zero padding 추가
- DenseBlock 사이에 transition layer추가 ( 1x1 conv, 2x2 avg pooling)
- 마지막 레이어에는 global avg pooling 사용
- 각 3개의 Dense Block은 32x32, 16x16, 8x8의 feature map이 반복
- 기본 DenseNet 설정은 {L=40, k=12}, {L=100, k=12}, {L=100, k=24}
- DenseNet-BC(B=bottleneck, C=Compression)는 {L=100, k=12}, {L=250, k=24}, {L=190, k=40}
- ImageNet에서는 입력 이미지 224x224에 대하여 맨 처음 conv를 7x7 kernel에 stride 2 적용
3. Experiments
- 아래 그림에서 ResNet은 augmentation을 한것과 안한것의 정답률 차이가 컸는데 DenseNet에서는 작았다 이는 DenseNet이 보다 더 overfitting에 강하다는 것을 보여준다
- 파라미터 개수도 이전보다 작고 정답률이 향상됨을 볼 수 있다

- Training
- 모든 데이터셋에 SGD 사용
- 초기 learning rate는 0.1로 하고 epochs가 50%, 75% 진행됐을 때 10씩 나눔
- ImageNet은 총 90 epochs에서 30, 60 때 10배씩 감소
- Weight decay 0.0001 이용, Nesterov momentum 0.9 사용 dampening 없이
- 다음에서 소개된 가중치 초기화 방식도 사용 ( K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.)
- Dropout 0.2 사용 ( 맨 처음 conv에서는 안 함)


4. Discussion
- 기존 ResNet과의 차이점은 단지 결합과 더함의 차이이다 하지만 이 작은 수정이 두 아키텍처의 동작을 크게 다르게 했다
- Input 결합의 직접적인 결과로 DenseNet은 이후의 모든 레이어의 feature map에 직접적으로 접근할 수 있었다
- 이는 네트워크 전체에서 feature reuse를 장려하고 더 딱 맞는(compact) 모델로 만들 수 있게 한다
- 모든 히든 레이어마다 classifier를 추가하는 Deeply-supervised Net과 비슷하고 차이는 하나의 loss function이 모든 레이어에 공유되므로 덜 복잡하다는 점이다
- 학습 중간에 무작위적으로 레이어를 삭제하는 stochastic depth regularization을 DenseNet에 이용하면 insight를 제공할 수 있을 거라 말한다
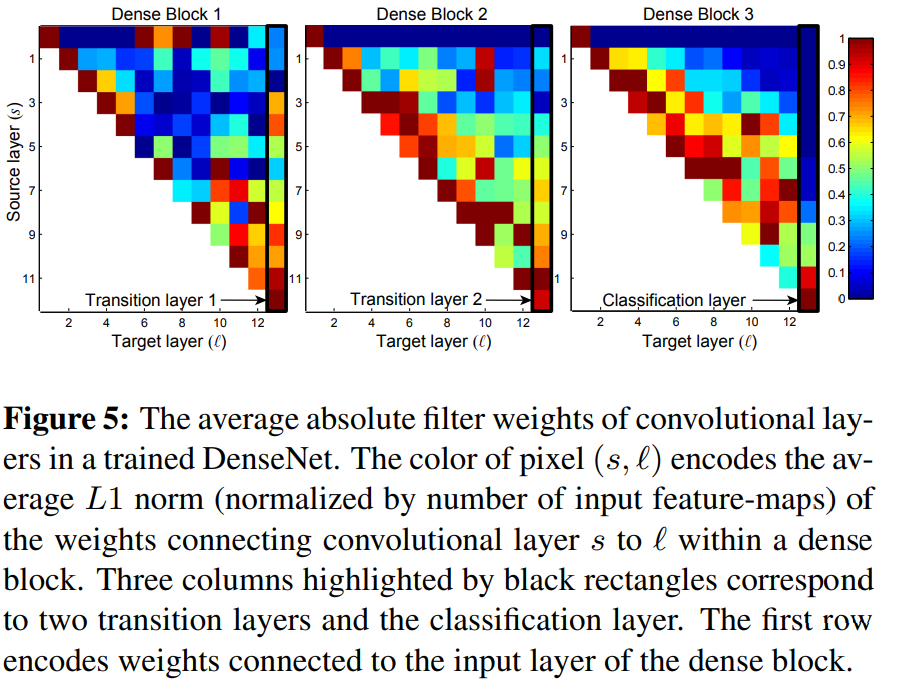
- 여기서 재밌는 그래프는 위의 feature reuse 그래프이다
- 실제로 모든 레이어가 이전 레이어의 feature-map에 접근하는지 알아보기 위해 레이어 s 와의 연결에 할당된 가중치 평균을 계산하였다
- 두 번째 세 번째 Dense block을 보면 맨 처음 source layer에서 뿌려지는 가중치가 일관되게 최소 가중치를 할당하는 것을 볼 수 있다 이는 transition layer에 의해 압축이 되었다는 것을 알 수 있다.
- 앞서 언급한 \(\theta\)에 의해 압축이 잘 됐다는 것을 알 수 있다
- 마지막 classification 레이어를 보면 Dense block 내부의 가중치를 전부 사용하지만 마지막 쪽 feature map에 집중하는 거로 보아 네트워크 후반에 생성된 더 높은 수준의 feature에 집중함을 알 수 있다