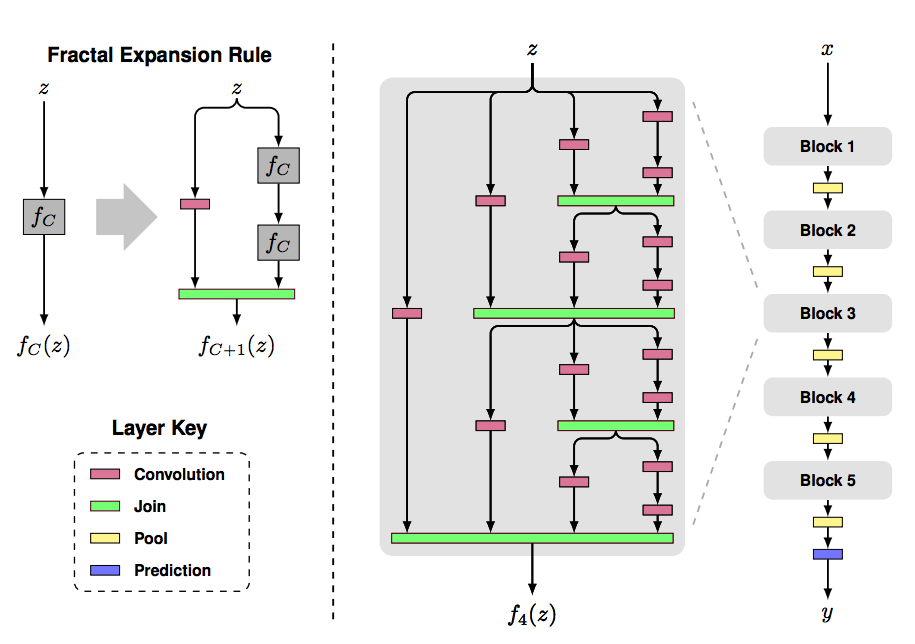
(2022-07-20) 현재에도 많이 사용하고 있는 방법인 CSP에 대한 논문이다
CSP는 계속돼서 사용되어 지금은 Modified CSPv6까지 나왔다
개인적인 생각으로는 기존 residual shortcut을 몇 개의(2~3개의) convolution마다 진행했다면 CSP shortcut은 그런 residual shortcut 몇 개마다 진행한다.
Abstract
- CSP : Cross Stage Partial Network
- 기존의 CNN들의 computation이 많이 소모되는 이유는 네트워크 최적화 내의 중복 기울기 정보(Duplicated gradient information) 때문이다
- CSPNet은 시작과 끝에서 feature map을 통합하여 기울기의 variability를 respect 한다
- 결과적으로, ImageNet dataset에서 동등한 정확도로 20% computations를 감소시켰다
- CSPNet은 쉽게 적용할 수 있고 기존 shortcut 방식들을 대체할 수 있는 일반적인 구조이다.
- transition layer : BN + 1x1 conv + 2x2 avg pooling
- growth rate : Dense Block을 지날 때마다 증가되는 feature map의 사이즈


1. Introduction
- Neural Network가 더 깊고 넓어질 수 록 더 강력함을 보여줬다
- 그러나 이런 확장 구조는 매우 많은 computations를 필요로 한다
- 이전의 몇몇 접근법에서는 모바일 GPU를 기준으로 설계되었다 ( depth-wise separable convolution)
depth-wise separable conv는 ASIC(Application-Specific Integrated Circuit)과 호환되지 않는다. - 이 제안의 초점은 기본 layer의 featuer map을 두 부분으로 나누어 제안하는 cross-stage hierarchy에 따라 mergeing 한다
- 중요 개념은 gradient의 흐름을 다른 두 개의 네트워크 경로에 나누는 것이다
- CSPNet에서 주로 다루는 문제는 3가지이다
1. CNN의 학습능력(learning ability) 강화
- 경량화하면서도 충분한 정확도를 유지
- ResNet, ResNeXt, DenseNet등에 쉽게 적용 가능하고 computation effort를 10~20%가량 줄이지만 정확도는 거의 떨어지지 않거나 outperform
2. Removing computational bottlenecks
- 너무 많은 computational bottleneck은 inference process에서 더 많은 cycles이 필요하게 된다
- utilization을 더 효율적으로 높이고 필요 없는 에너지 소모를 줄인다 ( 저자 중에 College of Artificial Intelligence and Green Energy National Chiao Tung Univ가 있는데 친환경에너지 쪽이어서 그런지 이런 이야기가 좀 있다)
- YOLOv3 기반 모델에서 computational bottleneck을 80%가량 감소시킨다
3. Reducing memory costs
- DRAN은 비싸고 크기도 큰데 DRAM사용량을 줄이면 ASIC의 비용을 감소시킬 수 있을 것이다
- 메모리 사용량을 줄이기 위해 cross-channel pooling을 이용 - feature pyramid 생성 과정에서 feature map의 compress를 수행한다
- PeleeNet에서 feature pyramids를 생성할 때 memory 사용량을 75% 감소할 수 있었다 - CSPNet은 CNN에서 학습 용량을 증가시킬 수 있고 작은 모델에서 더 좋은 정확도를 얻을 수 있다.
GTX 1080ti에서 109 FPS, 50%의 AP50을 얻었다
- 메모리 대역폭을 줄일 수 있었고 Nvidia jetson TX2에서 42% AP50, 49 FPS를 얻었다

2. Related work
- CNN architectures design
ResNeXt 저자가 width, depth의 channel보다 cardinality(gradient의 다양성)를 늘리는 게 더 효과적일 수 있다 했다
a. DenseNet
- 출력의 결과물을 그대로 concatenates 하여 다음 레이어의 인풋으로 사용했다 이러한 방식은 cardinality를 극대화할 수 있다
b. SparseNet
- dense connection은 exponentially spaced connection을 하여 parameter의 utilization을 효과적으로 개선할 수 있다 또한 높은 cardinality와 sparse connection이 gradient combination의 concept으로 왜 네트워크의 학습능력을 향상할 수 있는지 이유를 설명하고 partial ResNet(PRN)을 개발했다
3. Method
- Cross Stage Partial Network
- DenseNet
아래 수식을 보면 DenseNet의 경우 역전파에서 $$ g_0, g_1,... g_{k-1} $$ 가 중복되어 사용됨을 볼 수 있다
이런 중복은 다른 레이어에서 같은 값을 중복해서 사용함을 의미한다
- DenseNet
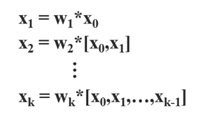

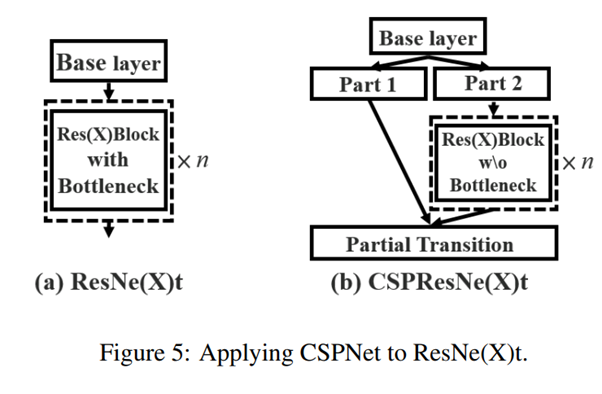
- 저자가 제안하는 CSPDenseNet은 입력 채널을 두 개의 파트로 분할한다
$$ x_0 = [x_0`, x_0``] $$ 두 개로 나누어진 파트는 스테이지의 마지막에서 직접적으로 연결된다 그리고 $$ x_0``$$ 는 dense block을 통과한다 - Dense layers의 출력 $$ [x_0``, x_1, ..., x_k]$$는 바로 transition layer를 통과하고 transition layer의 output $$x_t$$는 $$x_0``$$와 결합되고 바로 다른 transition layer를 통과하여 $$x_U$$를 생성한다.


- 위 공식을 보면 dense layer에서 들어오는 gradient 가 별도로 합쳐져 있음을 볼 수 있다 (gt)
또한 feature map x0`이 직접적으로 dense layers를 통과하지 않고 분리되어 통합된다
가중치 업데이트를 보면 두 갈래의 기울기 정보가 서로 중복되지 않는다. - CSPDenseNet은 DenseNet의 feature reuse장점은 유지하면서 동시에 gradient flow를 truncation 하여 중복되는 gradient info의 과도한 양을 방지한다
- Partial Dense Blcok
- Incerease gradient path : feature map복사를 사용하여 gradient paths가 doubled 되는 것을 완화
- balance computations of each layer : 일반적으로 base layer의 채널의 개수는 growth rate보다 크다(input C 64, growth rate 32, 64,...) CSP는 base layer의 반절만 사용하기 때문에 계산 병목 현상의 절반 가까이를 효과적으로 해결할 수 있다
- reduce memory traffic : 총 m개의 dense layer가 있을 때
$$ w\, \times \,h\, \times \, c,\, grouth\, rate\, :\, d, total \,m\, dense\, layers$$
dense layer의 CIO(Convolution Input, Output)는
$$ (c \times m ) + ((m^2 + m) \times d)/2 $$
이고 partial dense block의 CIO는
$$((c \times m)+(m^2 +m) \times d)/2$$
일반적으로 m과 d는 C보다 매우 작기 때문에 partial block이 반절 가까이 네트워크 메모리 traffic을 절약할 수 있다

- 저자는 3가지 다른 방식의 Feature fusion 방식을 소개한다
1. CSPDenseNet에 사용한 방식 두 갈래로 나누어진 경로에 하나는 Dense Block과 Transition layer를 지나고 그 뒤 두 갈래를 concatenate 한 후 다시 transition layer를 통과한다
2. Fusion First는 두 갈래 중 하는 Dense Block을 통과하고 그 뒤 두 갈래를 합친 후 transition layer를 통과한다
3. Fusion Last는 CSPDenseNet와 다르게 마지막에 두 갈래를 합치기만 하고 transition layer을 다시 지나가지 않는다 - 위의 Fusion First와 Fusion Last는 다른 영향을 보여주는데
Fusion First는 두 갈래로 나뉜 기울기를 먼저 합친 다음 transition layer로 들어가기 때문에 많은 양의 기울기가 재사용된다
Fusion Last는 한 방향만 transition layer를 지나가고 그 뒤 두 갈래를 합치기 때문에 기울기의 흐름이 잘리기 때문에 기울기 정보가 재사용되지 않는다 - Fusion first는 실험 결과 Imagenet 데이터셋에서 computations는 효과적으로 감소되었고 정확도는 0.1% 밖에 감소되지 않았다
Fusion Last 또한 computations는 감소되었지만 정확도가 1.5% 감소되었다

- 가정 1
- c 입력 채널 : 32
- m 몇개의 Dense layer : 3
- g growth rate : 32
$$ Dense \, layer : (32 \times 3) + ((3^2 + 3) \times 32)/2 = (96 + (12 \times 32)/2 = 96 + 384 / 2 = 288 $$
$$ partial \, dense \, block : ((32 \times 3) + ((3^2 + 3) \times 32))/2 = ((96 + (12 \times 32))/2 = (96 + 384) / 2 = 240 $$ - 가정 2
- c : 4
- m : 3
- g : 62
$$ Dense \, layer : (4 \times 3) + ((3^2 + 3) \times 64)/2 = (12 + (12 \times 64)/2 = 12 + 768 / 2 = 396 $$
$$ partial \, dense \, block : ((4 \times 3) + ((3^2 + 3) \times 64))/2 = ((12 + (12 \times 64))/2 = (12 + 768) / 2 = 390 $$
- 채널과 growth rate의 차이가 매우 커야 Dense layer의 CIO가 더 커진다

4. Experiments
- Computational Bottleneck
기존의 ResXBlock에서 bottleneck layers를 제거하여 채널의 크기 변경을 감소시킴으로 인해 22%가량 computations를 감소시켰다


논문 : https://arxiv.org/pdf/1911.11929.pdf
'Machine Learning > 논문 리뷰' 카테고리의 다른 글
| (8) YOLOX : Exceeding YOLO Series in 2021 (2021) (0) | 2022.06.12 |
|---|---|
| (7) Learning Spatiotemporal Features with 3D Convolutional Networks (2015) (1) | 2022.04.17 |
| (6) DenseNet : Densly Connected Convolutional Networks (2017) (0) | 2022.04.10 |
| (5) ResNet : Deep Residual Learning for Image Recognition(2015) (0) | 2022.03.14 |
| (4) GoogLeNet(Goog-Le-Net) Going Deeper with Convolutions (0) | 2022.02.20 |